Getting started with Braintrust
Braintrust helps evaluate your LLM app, so you can quickly and confidently ship to production. We provide a Typescript/Python library to log evaluation experiments and production data.
Install Braintrust libraries
Start by installing the Typescript or Python library.
npm install braintrust autoevalsor
yarn add braintrust autoevalsCreate a simple evaluation script
First, create a simple evaluation script. Make sure to follow the naming conventions for your language. Typescript
files should be named *.eval.ts and Python files should be named eval_*.py.
import { Eval } from "braintrust";
import { LevenshteinScorer } from "autoevals";
Eval("Say Hi Bot", {
data: () => {
return [
{
input: "Foo",
expected: "Hi Foo",
},
{
input: "Bar",
expected: "Hello Bar",
},
]; // Replace with your eval dataset
},
task: (input) => {
return "Hi " + input; // Replace with your LLM call
},
scores: [LevenshteinScorer],
});This script sets up the basic scaffolding of an evaluation:
datais an array or iterator of data you'll evaluatetaskis a function that takes in an input and returns an outputscoresis an array of scoring functions that will be used to score the tasks's output
Create an API key
Next, create an API key to authenticate your evaluation script. You can create an API key in the settings page.
Run your evaluation script
Run your evaluation script with the following command:
BRAINTRUST_API_KEY=<YOUR_API_KEY> npx braintrust eval tutorial.eval.tsOnce the command runs, you'll see a link to your experiment.
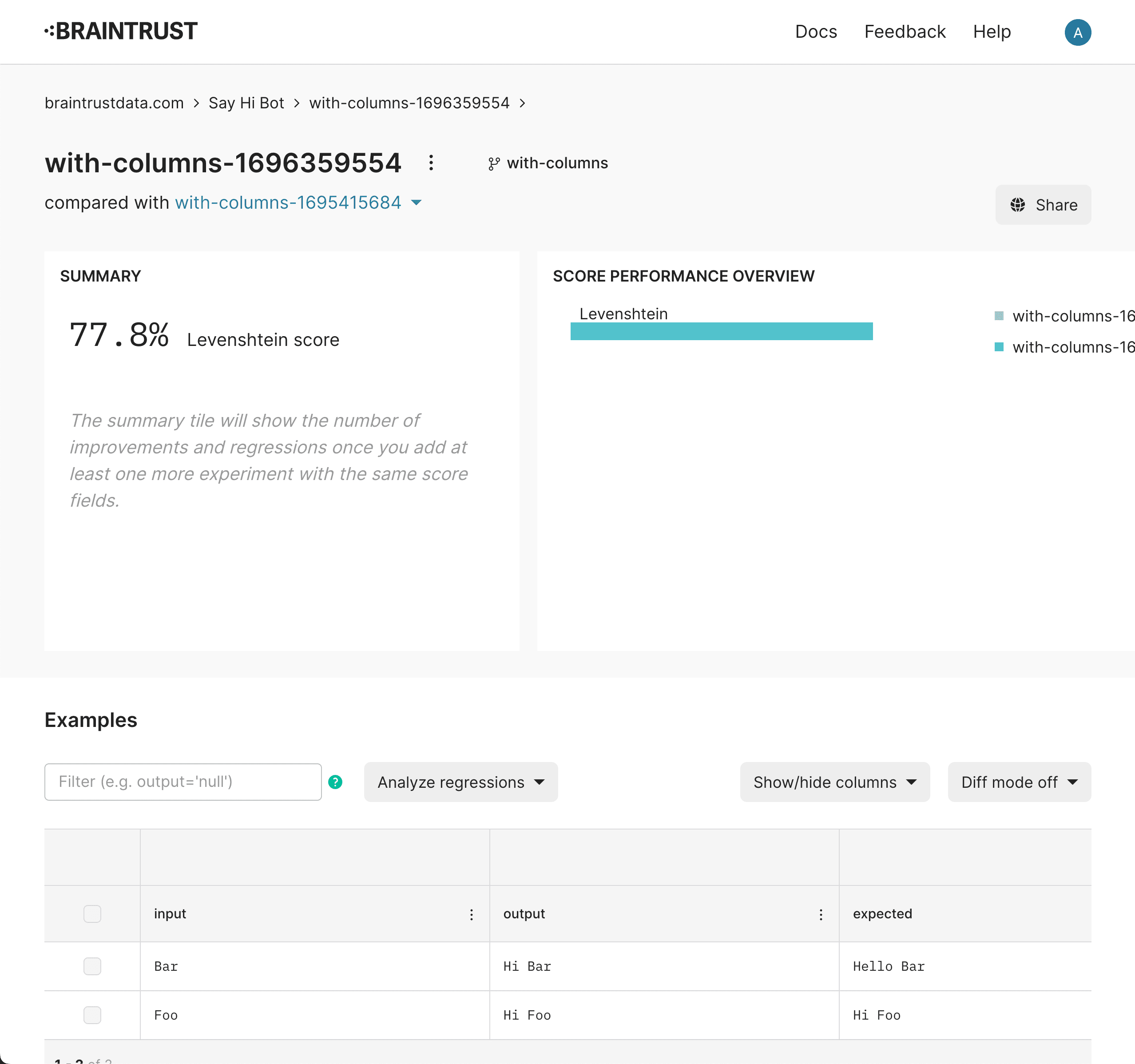
View your results
Congrats, you just ran an eval! You should see a dashboard like this when you load your experiment. This view is called the experiment view, and as you use Braintrust, we hope it becomes your trusty companion each time you change your code and want to run an eval.
The experiment view allows you to look at high level metrics for performance, dig into individual examples, and compare your LLM app's performance over time.
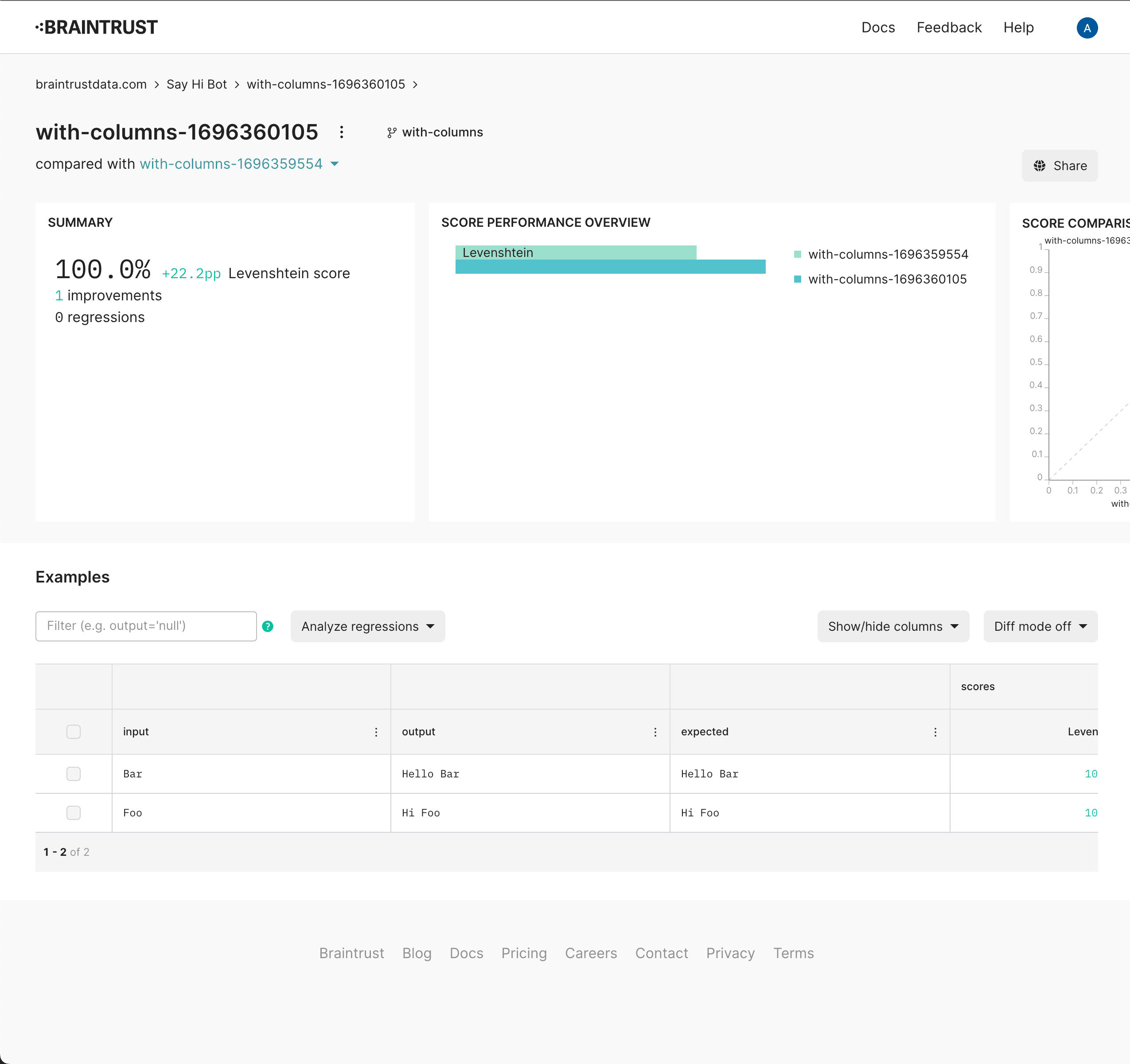
Run another experiment
Now that you've run your first eval, you'll notice that we only achieved a 77.8% score. Can you improve that?
Next Steps
- Dig into our Evals guide to learn more about how to run evals.
- Walk through our Python tutorial and notebook on how to use Braintrust to build a reliable SQL generation app.
- Look at our AI app examples and templates to get your project started quickly.
- Read about Braintrust's platform and architecture.