Run evaluations
This guide walks through how to run evaluations in Braintrust, one level deeper. If you haven't already, make sure to read the quickstart guide first. Before proceeding, you should be comfortable with creating an experiment in Braintrust in Typescript or Python and have an API key.
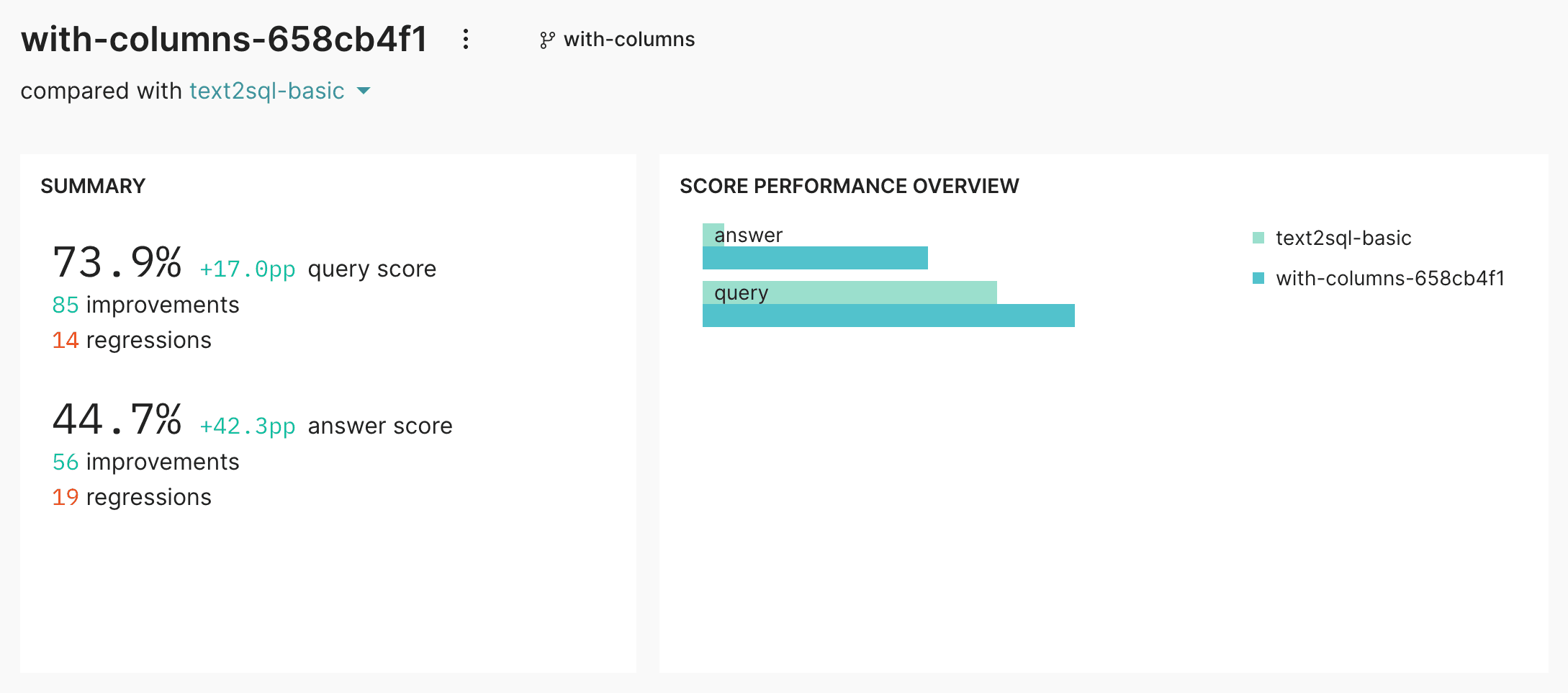
What are evaluations?
Evaluations are a method to measure the performance of your AI application. Performance is an overloaded word in AI—in traditional software it means "speed" (e.g. the number of milliseconds required to complete a request), but in AI, it usually means "accuracy".
Because AI software has non-deterministic behavior, it's critical to understand performance while you're developing, and before you ship. It's also important to track performance over time. It's unlikely that you'll ever hit 100% correctness, but it's important that for the metrics you care about, you're steadily improving.
Evaluations in Braintrust allow you to capture this craziness into a simple, effective workflow that enables you ship more reliable, higher quality products. If you adopt an evaluation-driven development mentality, not only will you ship faster, but you'll also be better prepared to explore more advanced AI techniques, including training/fine-tuning your own models, dynamically routing inputs, and scaling your AI team.
Pre-requisites
To get started with evaluation, you need some data (5-10 examples is a fine starting point!) and a task function. The data should have an input field (which could be complex JSON, or just a string) and ideally an expected output field, although this is not required.
It's a common misnomer that you need a large volume of perfectly labeled evaluation data, but that's not the case. In practice, it's better to assume your data is noisy, AI model is imperfect, and scoring methods are a little bit wrong. The goal of evaluation is to assess each of these components and improve them over time.
Running evaluations
Braintrust allows you to create evaluations directly in your code, and run them in your development workflow or CI/CD pipeline.
There are two ways to create evaluations:
- A high level framework that allows you to declaratively define evaluations
- A logging SDK that allows you to directly report evaluation results
Before proceeding, make sure to install the Braintrust Typescript or Python SDK and the autoevals library.
npm install braintrust autoevalsor
yarn add braintrust autoevalsEval framework
The eval framework allows you to declaratively define evaluations in your code. Inspired by tools like
Jest, you can define a set of evaluations in files named *.eval.ts or *.eval.js (Node.js)
or eval_*.py (Python).
Example
import { Eval } from "braintrust";
import { Factuality } from "autoevals";
Eval("Say Hi Bot", {
data: () => {
return [
{
input: "David",
expected: "Hi David",
},
]; // Replace with your eval dataset
},
task: (input) => {
return "Hi " + input; // Replace with your LLM call
},
scores: [Factuality],
});Each Eval() statement corresponds to a Braintrust project. The first argument is the name of the project,
and the second argument is an object with the following properties:
data, a function that returns an evaluation dataset: a list of inputs, expected outputs, and metadatatask, a function that takes a single input and returns an output like a LLM completionscores, a set of scoring functions that take an input, output, and expected value and return a score
Executing
Once you define one or more evaluations, you can run them using the braintrust eval command. Make sure to set
the BRAINTRUST_API_KEY environment variable before running the command.
export BRAINTRUST_API_KEY="YOUR_API_KEY"
npx braintrust eval basic.eval.tsnpx braintrust eval [file or directory] [file or directory] ...This command will run all evaluations in the specified files and directories. As they run, they will automatically log results to Braintrust and display a summary in your terminal.
Watch-mode
You can run evaluations in watch-mode by passing the --watch flag. This will re-run evaluations whenever any of
the files they depend on change.
Scoring functions
A scoring function allows you to compare the expected output of a task to the actual output and produce a score
between 0 and 1. We encourage you to create multiple scores to get a well rounded view of your application's
performance. You can use the scores provided by Braintrust's autoevals library by simply
referencing them, e.g. Factuality, in the scores array.
Custom evaluators
You can also define your own score, e.g.
import { Eval } from "braintrust";
import { Factuality } from "autoevals";
const exactMatch = (args: { input; output; expected? }) => {
return {
name: "Exact match",
score: args.output === args.expected ? 1 : 0,
};
};
Eval("Say Hi Bot", {
data: () => {
return [
{
input: "David",
expected: "Hi David",
},
]; // Replace with your eval dataset
},
task: (input) => {
return "Hi " + input; // Replace with your LLM call
},
scores: [Factuality, exactMatch],
});Additional fields
Certain scorers, like ClosedQA, allow additional fields to be passed in. You can pass them in via a wrapper function, e.g.
import { Eval, wrapOpenAI } from "braintrust";
import { ClosedQA } from "autoevals";
import { OpenAI } from "openai";
const openai = wrapOpenAI(new OpenAI());
const closedQA = (args: { input: string; output: string }) => {
return ClosedQA({
input: args.input,
output: args.output,
criteria:
"Does the submission specify whether or not it can confidently answer the question?",
});
};
Eval("QA bot", {
data: () => [
{
input: "Which insect has the highest population?",
expected: "ant",
},
],
task: async (input) => {
const response = await openai.chat.completions.create({
model: "gpt-3.5-turbo",
messages: [
{
role: "system",
content:
"Answer the following question. Specify how confident you are (or not)",
},
{ role: "user", content: "Question: " + input },
],
});
return response.choices[0].message.content || "Unknown";
},
scores: [closedQA],
});Troubleshooting
Stack traces
By default, the evaluation framework swallows errors in individual tasks, reports them to Braintrust,
and prints a single line per error to the console. If you want to see the full stack trace for each
error, you can pass the --verbose flag.
Skipping scorers
Sometimes, a scorer is only relevant to a subset of your evaluation data. For example, if you're
evaluating a chatbot, you might want to use a scoring function that measures whether calculator-style inputs
are correctly answered. To do this, you can simply return null from a scoring function if it's not relevant.
import { NumericDiff } from "autoevals";
const calculatorAccuracy = ({ input, output }) => {
if (input.type !== "calculator") {
return null;
}
return NumericDiff({ output, expected: calculatorTool(input.text) });
};
...Scores with null values will be ignored when computing the overall score, improvements/regressions, and
summary metrics (like standard deviation).
Trials
It is often useful to run each input in an evaluation multiple times, to get a sense of the variance in
responses and get a more robust overall score. Braintrust supports trials as a first-class concept, allowing
you to run each input multiple times. Behind the scenes, Braintrust will intelligently aggregate the results
by bucketing rows with the same input value and computing summary statistics for each bucket.
To enable trials, add a trialCount/trial_count property to your evaluation:
import { Eval } from "braintrust";
import { Factuality } from "autoevals";
Eval("Say Hi Bot", {
data: () => {
return [
{
input: "David",
expected: "Hi David",
},
]; // Replace with your eval dataset
},
task: (input) => {
return "Hi " + input; // Replace with your LLM call
},
scores: [Factuality],
trialCount: 10,
});Hill climbing
Sometimes you do not have expected values, and instead want to use a previous experiment as a baseline. Hill climbing is inspired by, but not exactly the same as, the term used in numerical optimization. In the context of Braintrust, hill climbing is a way to iteratively improve a model's performance by comparing new experiments to previous ones. This is especially useful when you don't have a pre-existing benchmark to evaluate against.
Braintrust supports hill climbing as a first-class concept, allowing you to use a previous experiment's output
field as the expected field for the current experiment. Autoevals also includes a number of scoreres, like
Summary and Battle, that are designed to work well with hill climbing.
To enable hill climbing, use BaseExperiment() in the data field of an eval:
import { Battle } from "autoevals";
import { Eval, BaseExperiment } from "braintrust";
Eval("Say Hi Bot", {
data: BaseExperiment(),
task: (input) => {
return "Hi " + input; // Replace with your LLM call
},
scores: [Battle],
});That's it! Braintrust will automatically pick the best base experiment, either using git metadata if available or
timestamps otherwise, and then populate the expected field by merging the expected and output
field of the base experiment. This means that if you set expected values, e.g. through the UI while reviewing results,
they will be used as the expected field for the next experiment.
Using a specific experiment
If you want to use a specific experiment as the base experiment, you can pass the name field to BaseExperiment():
import { Battle } from "autoevals";
import { Eval, BaseExperiment } from "braintrust";
Eval("Say Hi Bot", {
data: BaseExperiment({ name: "main-123" }),
task: (input) => {
return "Hi " + input; // Replace with your LLM call
},
scores: [Battle],
});Scoring considerations
Often while hill climbing, you want to use two different types of scoring functions:
- Methods that do not require an expected value, e.g.
ClosedQA, so that you can judge the quality of the output purely based on the input and output. This measure is useful to track across experiments, and it can be used to compare any two experiments, even if they are not sequentially related. - Comparative methods, e.g.
BattleorSummary, that accept anexpectedvalue but do not treat it as a ground truth. Generally speaking, if you score > 50% on a comparative method, it means you're doing better than the base on average. To learn more about howBattleandSummarywork, check out their prompts.
Tracing
Braintrust allows you to trace detailed debug information and metrics about your application that you can use to measure performance and debug issues. The trace is a tree of spans, where each span represents an expensive task, e.g. an LLM call, vector database lookup, or API request.
Spans automatically log the time they are started and ended. Furthermore, each
call to experiment.log() is encapsulated in its own trace, starting at the
time of the previous log statement and ending at the completion of the current.
Thus by default, you can inspect how long individual invocations of
experiment.log() took from start to finish.
For more detailed tracing, you can wrap existing code with the
braintrust.traced function. Inside the wrapped function, you can log
incrementally to braintrust.currentSpan(). For example, you can progressively
log the input, output, and expected value of a task, and then log a score at the
end:
import { traced } from "braintrust";
async function callModel(input) {
return traced(
async (span) => {
const messages = { messages: [{ role: "system", text: input }] };
span.log({ input: messages });
// Replace this with a model call
const result = {
content: "China",
latency: 1,
prompt_tokens: 10,
completion_tokens: 2,
};
span.log({
output: result.content,
metrics: {
latency: result.latency,
prompt_tokens: result.prompt_tokens,
completion_tokens: result.completion_tokens,
},
});
return result.content;
},
{
name: "My AI model",
}
);
}
const exactMatch = (args: { input; output; expected? }) => {
return {
name: "Exact match",
score: args.output === args.expected ? 1 : 0,
};
};
Eval("My Evaluation", {
data: () => [
{ input: "Which country has the highest population?", expected: "China" },
],
task: async (input, { span }) => {
return await callModel(input);
},
scores: [exactMatch],
});
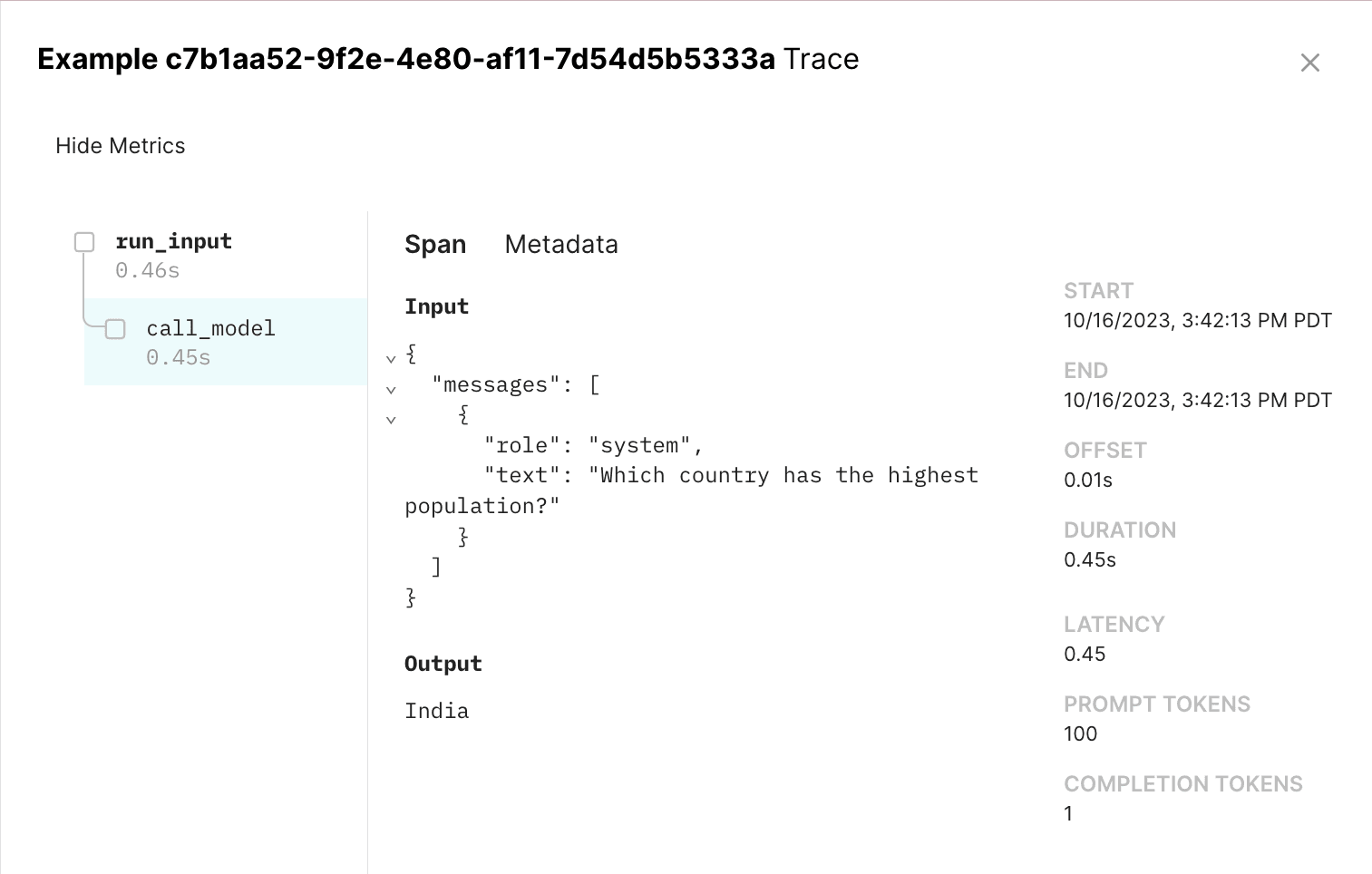
This results in a span tree you can visualize in the UI by clicking on each row in the experiment:

Directly using the SDK
The SDK allows you to report evaluation results directly from your code, without using the Eval() function.
This is useful if you want to structure your own complex evaluation logic, or integrate Braintrust with an
existing testing or evaluation framework.
import * as braintrust from "braintrust";
import { Factuality } from "autoevals";
async function runEvaluation() {
const experiment = braintrust.init("Say Hi Bot");
const dataset = [{ input: "David", expected: "Hi David" }]; // Replace with your eval dataset
for (const { input, expected } of dataset) {
const output = "Hi David"; // Replace with your LLM call
const { name, score } = await Factuality({ input, output, expected });
await experiment.log({
input,
output,
expected,
scores: {
[name]: score,
},
metadata: { type: "Test" },
});
}
const summary = await experiment.summarize();
console.log(summary);
return summary;
}
runEvaluation();Refer to the tracing guide for examples of how to trace evaluations using the low-level SDK. For more details on how to use the low level SDK, see the Python or Node.js documentation.
Integrate evals into tests
Now that you've created an evaluation function, it's easy to integrate evals into your testing workflow.
import { expect, test } from "vitest";
test(
"Run Evaluation",
async () => {
const evaluationRun = await runEvaluation();
// Make sure each score is above 0.5
Object.values(evaluationRun.scores ?? {}).forEach((score) =>
expect(score.score).toBeGreaterThan(0.5),
);
},
{ timeout: 1000000 },
);Troubleshooting
Tuning Parameters
The SDK includes several tuning knobs that may prove useful for debugging.
-
BRAINTRUST_SYNC_FLUSH: By default, the SDKs will log to the backend API in the background, asynchronously. Logging is automatically batched and retried upon encountering network errors. If you wish to have fine-grained control over when logs are flushed to the backend, you may setBRAINTRUST_SYNC_FLUSH=1. When true, flushing will only occur when you runExperiment.flush(or any of the other object flush methods). If the flush fails, the SDK will raise an exception which you can handle. -
BRAINTRUST_MAX_REQUEST_SIZE: The SDK logger batches requests to save on network roundtrips. The batch size is tuned for the AWS lambda gateway, but you may adjust this if your backend has a different max payload requirement. -
BRAINTRUST_DEFAULT_BATCH_SIZE: The maximum number of individual log messages that are sent to the network in one payload. -
BRAINTRUST_NUM_RETRIES: The number of times the logger will attempt to retry network requests before failing. -
BRAINTRUST_QUEUE_SIZE(Python only): The maximum number of elements in the logging queue. This value limits the memory usage of the logger. In sync-flush mode, the queue size is defaulted to unlimited, and you may set it to unlimited manually by passingBRAINTRUST_QUEUE_SIZE=0.