Release notes
Week of 2024-02-19
We rolled out a breaking change to the REST API that renames the
output field to expected on dataset records. This change brings
the API in line with last week's update to
the Braintrust SDK. For more information, refer to the REST API docs
for dataset records (insert
and fetch).
Week of 2024-02-12
We are rolling out a change to dataset records that renames the output
field to expected. If you are using the SDK, datasets will still fetch
records using the old format for now, but we recommend future-proofing
your code by setting the useOutput / use_output flag to false when
calling initDataset() / init_dataset(), which will become the default
in a future version of Braintrust.
When you set useOutput to false, your dataset records will contain
expected instead of output. This makes it easy to use them with
Eval(...) to provide expected outputs for scoring, since you'll
no longer have to manually rename output to expected when passing
data to the evaluator:
import { Eval, initDataset } from "braintrust";
import { Levenshtein } from "autoevals";
Eval("My Eval", {
data: initDataset("Existing Dataset", { useOutput: false }), // Records will contain `expected` instead of `output`
task: (input) => "foo",
scores: [Levenshtein],
});Here's an example of how to insert and fetch dataset records using the new format:
import { initDataset } from "braintrust";
// Currently `useOutput` defaults to true, but this will change in a future version of Braintrust.
const dataset = initDataset("My Dataset", { useOutput: false });
dataset.insert({
input: "foo",
expected: { result: 42, error: null }, // Instead of `output`
metadata: { model: "gpt-3.5-turbo" },
});
await dataset.flush();
for await (const record of dataset) {
console.log(record.expected); // Instead of `record.output`
}Week of 2024-02-05
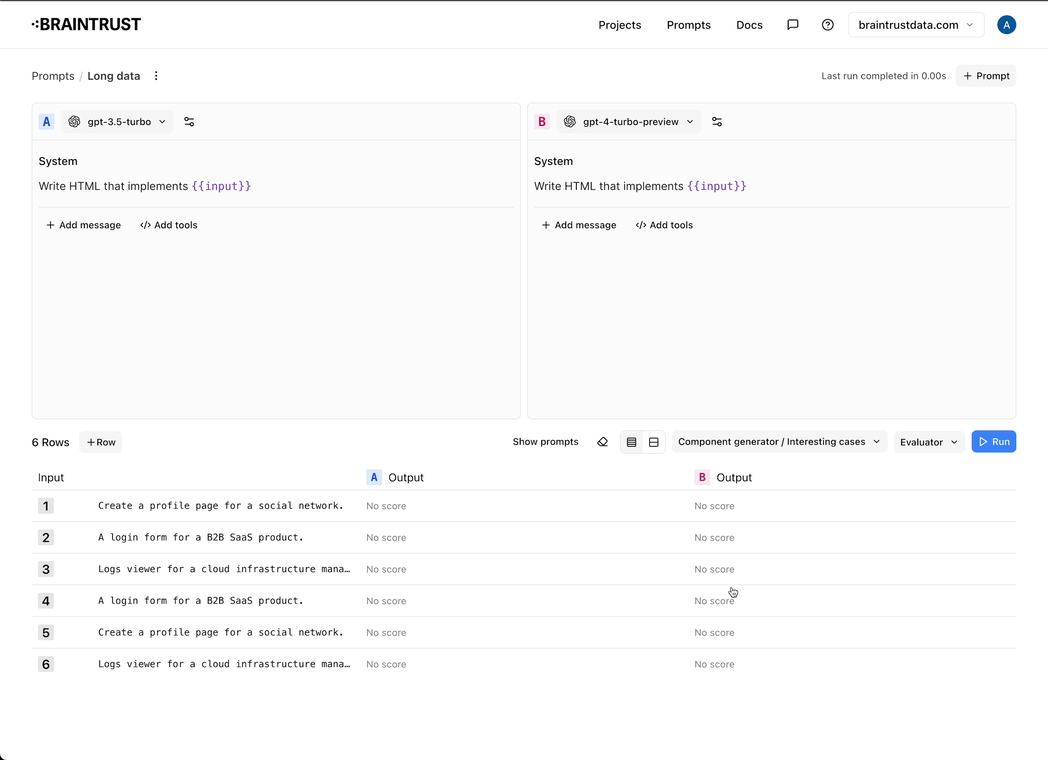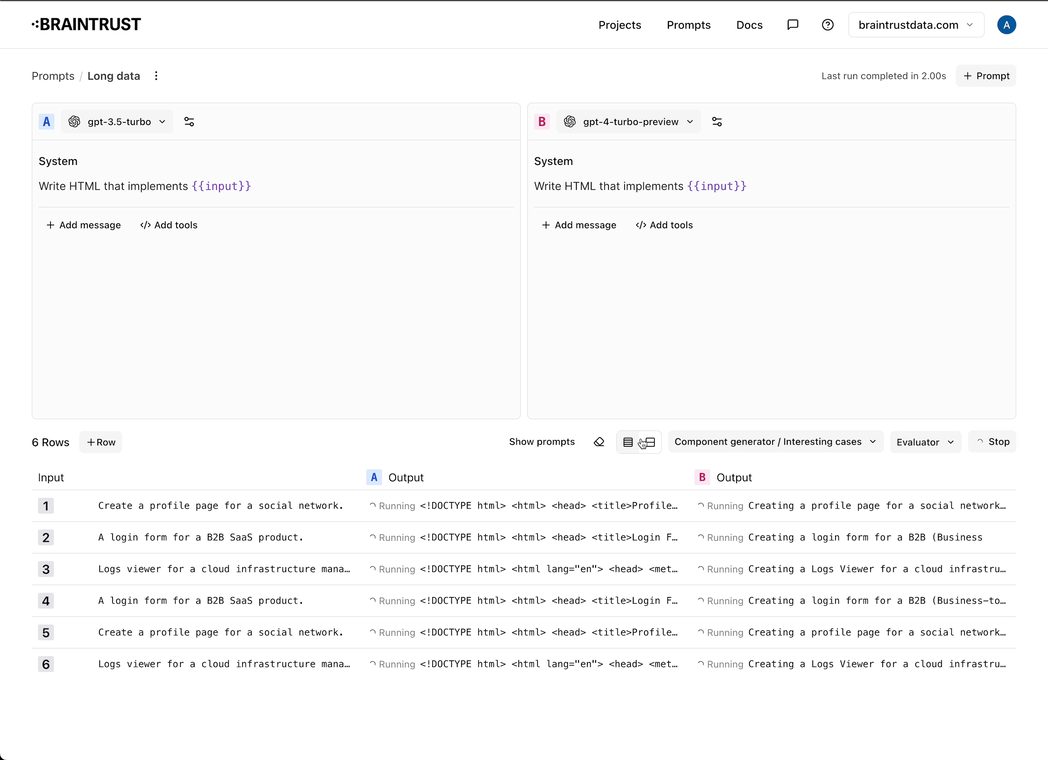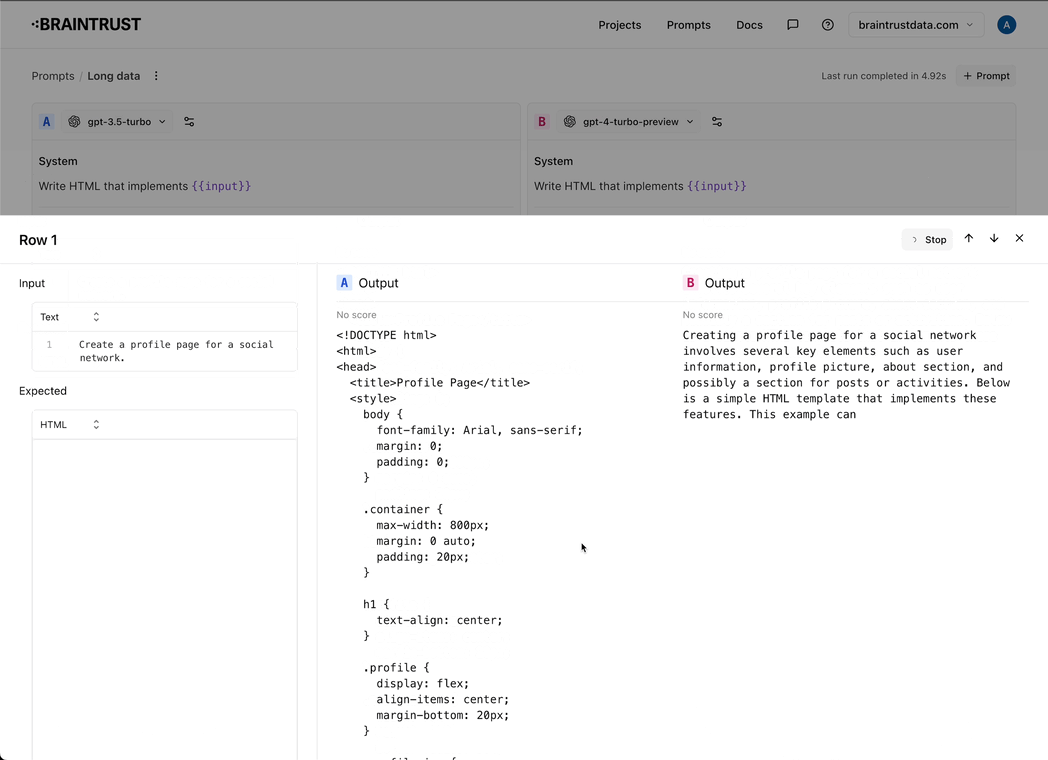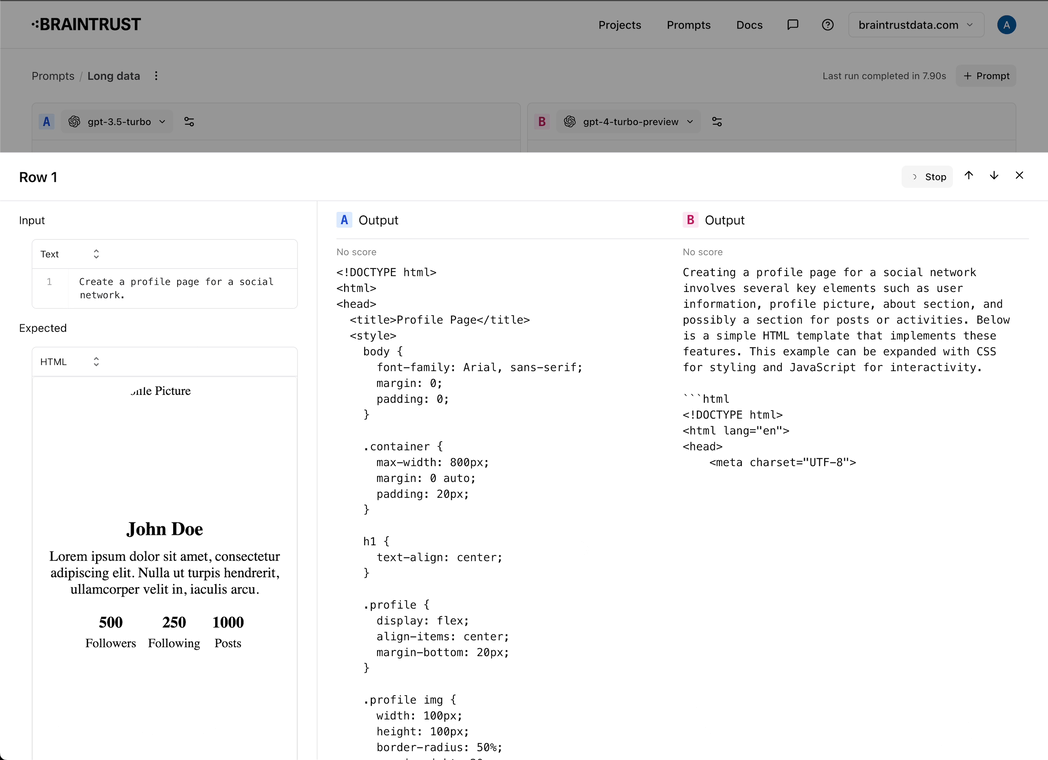
- Tons of improvements to the prompt playground:
- A new "compact" view, that shows just one line per row, so you can quickly scan across rows. You can toggle between the two modes.
- Loading indicators per cell
- The run button transforms into a "Stop" button while you are streaming data
- Prompt variables are now syntax highlighted in purple and use a monospace font
- Tab now autocompletes
- We no longer auto-create variables as you're typing (was causing more trouble than helping)
- Slider params like
max_tokensare now optional
- Cloudformation now supports more granular RDS configuration (instance type, storage, etc)
- Support optional slider params
- Made certain parameters like
max_tokensoptional. - Accompanies pull request https://github.com/braintrustdata/braintrust-proxy/pull/23.
- Made certain parameters like
- Lots of style improvements for tables.
- Fixed filter bar styles.
- Rendered JSON cell values using monospace type.
- Adjusted margins for horizontally scrollable tables.
- Implemented a smaller size for avatars in tables.
- Deleting a prompt takes you back to the prompts tab
Week of 2024-01-29
- New REST API.
- Cookbook of common use cases and examples.
- Support for custom models in the playground.
- Search now works across spans, not just top-level traces.
- Show creator avatars in the prompt playground
- Improved UI breadcrumbs and sticky table headers
Week of 2024-01-22
- UI improvements to the playground.
- Added an example of closed QA / extra fields.
- New YAML parser and new syntax highlighting colors for data editor.
- Added support for enabling/disabling certain git fields from collection (in org settings and the SDK).
- Added new GPT-3.5 and 4 models to the playground.
- Fixed scrolling jitter issue in the playground.
- Made table fields in the prompt playground sticky.
Week of 2024-01-15
- Added ability to download dataset as CSV
- Added YAML support for logging and visualizing traces
- Added JSON mode in the playground
- Added span icons and improved readability
- Enabled shift modifier for selecting multiple rows in Tables
- Improved tables to allow editing expected fields and moved datasets to trace view
Week of 2024-01-08
- Released new Docker deployment method for self hosting
- Added ability to manually score results in the experiment UI
- Added comments and audit log in the experiment UI
Week of 2024-01-01
- Added ability to upload dataset CSV files in prompt playgrounds
- Published new guide for tracing and logging your code
- Added support to download experiment results as CSVs
Week of 2023-12-25
- API keys are now scoped to organizations, so if you are part of multiple orgs, new API keys will only permit access to the org they belong to.
- You can now search for experiments by any metadata, including their name, author, or even git metadata.
- Filters are now saved in URL state so you can share a link to a filtered view of your experiments or logs.
- Improve performance of project page by optimizing API calls.
We made several cleanups and improvements to the low-level typescript and python SDKs (0.0.86). If you use the Eval framework, nothing should change for you, but keep in mind the following differences if you use the manual logging functionality:
- Simplified the low-level tracing API (updated docs coming soon!)
- The current experiment and current logger are now maintained globally
rather than as async-task-local variables. This makes it much simpler to
start tracing with minimal code modification. Note that creating
experiments/loggers with
withExperiment/withLoggerwill now set the current experiment globally (visible across all async tasks) rather than local to a specific task. You may passsetCurrent: false/set_current=Falseto avoid setting the global current experiment/logger. - In python, the
@traceddecorator now logs the function input/output by default. This might interfere with code that already logs input/output inside thetracedfunction. You may passnotrace_io=Trueas an argument to@tracedto turn this logging off. - In typescript, the
tracedmethod can start spans under the global logger, and is thus async by default. You may passasyncFlush: trueto these functions to make the traced function synchronous. Note that if the function tries to trace under the global logger, it must also haveasyncFlush: true. - Removed the
withCurrent/with_currentfunctions - In typescript, the
Span.tracedmethod now acceptsnameas an optional argument instead of a required positional param. This matches the behavior of all other instances oftraced.nameis also now optional in python, but this doesn't change the function signature.
- The current experiment and current logger are now maintained globally
rather than as async-task-local variables. This makes it much simpler to
start tracing with minimal code modification. Note that creating
experiments/loggers with
ExperimentsandDatasetsare now lazily-initialized, similar toLoggers. This means all write operations are immediate and synchronous. But any metadata accessor methods ([Experiment|Logger].[id|name|project]) are now async.- Undo auto-inference of
force_loginifloginis invoked with different params than last time. Nowloginwill only re-login ifforceLogin: true/force_login=Trueis provided.
Week of 2023-12-18
- Dropped the official 2023 Year-in-Review dashboard. Check out yours here!

- Improved ergonomics for the Python SDK:
- The
@traceddecorator will automatically log inputs/outputs - You no longer need to use context managers to scope experiments or loggers.
- The
- Enable skew protection in frontend deploys, so hopefully no more hard refreshes.
- Added syntax highlighting in the sidepanel to improve readability.
- Add
jsonlmode to the eval CLI to log experiment summaries in an easy-to-parse format.
Week of 2023-12-11
- Released new trials feature to rerun each input multiple times and collect aggregate results for a more robust score.
- Added ability to run evals in the prompt playground. Use your existing dataset and the autoevals functions to score playground outputs.
- Released new version of SDK (0.0.81) including a small breaking change. When setting the experiment name in the
Evalfunction, theexprimentNamekey pair should be moved to a top level argument. before:
Eval([eval_name], {
...,
metadata: {
experimentName: [experimentName]
}
})after:
Eval([eval_name], {
...,
experimentName: [experimentName]
})- Added support for Gemini and Mistral Platform in AI proxy and playground
Week of 2023-12-4
- Enabled the prompt playground and datasets for free users
- Added Together.ai models including Mixtral to AI Proxy
- Turned prompts tab on organization view into a list
- Removed data row limit for the prompt playground
- Enabled configuration for dark mode and light mode in settings
- Added automatic logging of a diff if an experiment is run on a repo with uncommitted changes
Week of 2023-11-27
- Added experiment search on project view to filter by experiment name
- Upgraded AI Proxy to support tracking Prometheus metrics
- Modified Autoevals library to use the AI proxy
- Upgraded Python braintrust library to parallelize evals
- Optimized experiment diff view for performance improvements
Week of 2023-11-20
- Added support for new Perplexity models (ex: pplx-7b-online) to playground
- Released AI proxy: access many LLMs using one API w/ caching
- Added load balancing endpoints to AI proxy
- Updated org-level view to show projects and prompt playground sessions
- Added ability to batch delete experiments
- Added support for Claude 2.1 in playground
Week of 2023-11-13
- Made experiment column resized widths persistent
- Fixed our libraries including Autoevals to work with OpenAI’s new libraries

- Added support for function calling and tools in our prompt playground
- Added tabs on a project page for datasets, experiments, etc.
Week of 2023-11-06
- Improved selectors for diffing and comparison modes on experiment view
- Added support for new OpenAI models (GPT4 preview, 3.5turbo-1106) in playground
- Added support for OS models (Mistral, Codellama, Llama2, etc.) in playground using Perplexity's APIs
Week of 2023-10-30
- Improved experiment sidebar to be fully responsive and resizable
- Improved tooltips within the web UI
- Multiple performance optimizations and bug fixes
Week of 2023-10-23
-
Improved prompt playground variable handling and visualization
-
Added time duration statistics per row to experiment summaries
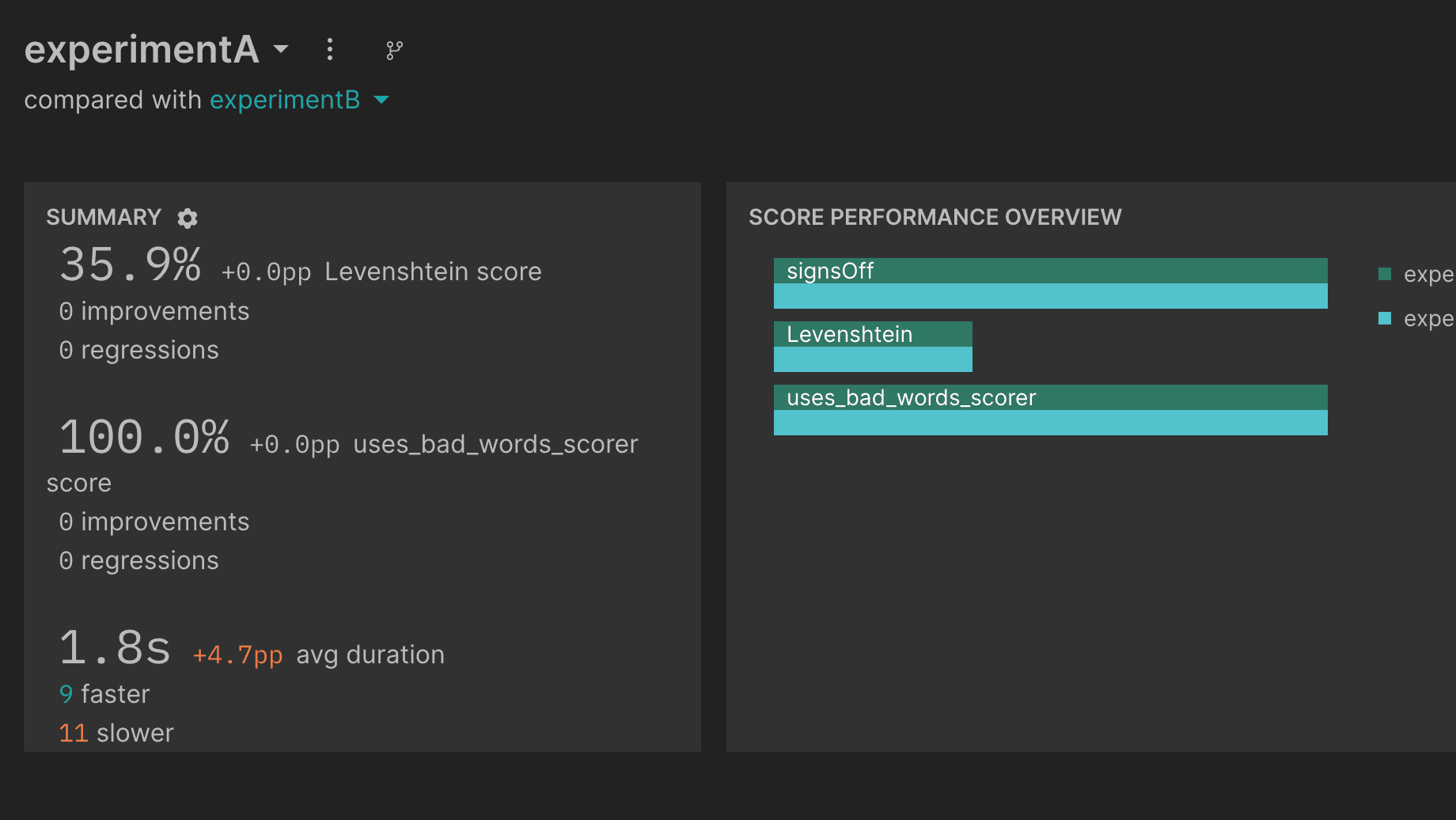
- Multiple performance optimizations and bug fixes
Week of 2023-10-16
- Launched new tracing feature: log and visualize complex LLM chains and executions.
- Added a new “text-block” prompt type in the playground that just returns a string or variable back without a LLM call (useful for chaining prompts and debugging)
- Increased default # of rows per page from 10 to 100 for experiments
- UI fixes and improvements for the side panel and tooltips
- The experiment dashboard can be customized to show the most relevant charts
Week of 2023-10-09
- Performance improvements related to user sessions
Week of 2023-10-02
- All experiment loading HTTP requests are 100-200ms faster
- The prompt playground now supports autocomplete
- Dataset versions are now displayed on the datasets page
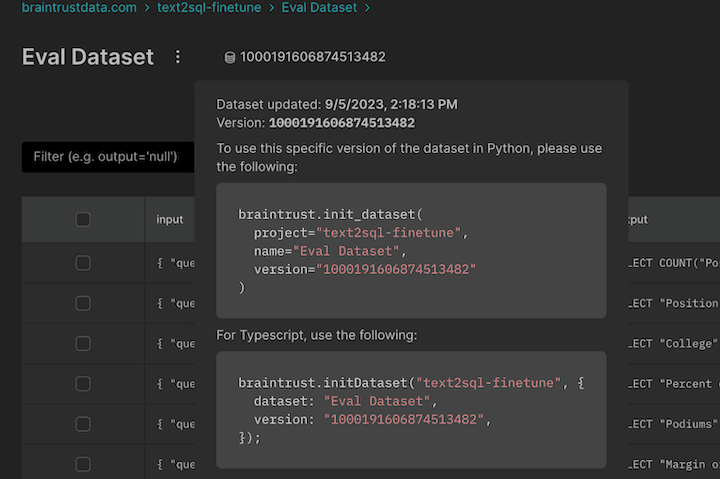
- Projects in the summary page are now sorted alphabetically
- Long text fields in logged data can be expanded into scrollable blocks
- We evaluated the Alpaca evals leaderboard in Braintrust
- New tutorial for finetuning GPT3.5 and evaluating with Braintrust
Week of 2023-09-18
- The Eval framework is now supported in Python! See the updated evals guide for more information:
from braintrust import Eval
from autoevals import LevenshteinScorer
Eval(
"Say Hi Bot",
data=lambda: [
{
"input": "Foo",
"expected": "Hi Foo",
},
{
"input": "Bar",
"expected": "Hello Bar",
},
], # Replace with your eval dataset
task=lambda input: "Hi " + input, # Replace with your LLM call
scores=[LevenshteinScorer],
)- Onboarding and signup flow for new users
- Switch product font to Inter
Week of 2023-09-11
-
Big performance improvements for registering experiments (down from ~5s to <1s). Update the SDK to take advantage of these improvements.
-
New graph shows aggregate accuracy between experiments for each score.

-
Throw errors in the prompt playground if you reference an invalid variable.
-
A significant backend database change which significantly improves performance while reducing costs. Please contact us if you have not already heard from us about upgrading your deployment.
-
No more record size constraints (previously, strings could be at most 64kb long).
-
New autoevals for numeric diff and JSON diff
Week of 2023-09-05
- You can duplicate prompt sessions, prompts, and dataset rows in the prompt playground.
- You can download prompt sessions as JSON files (including the prompt templates, prompts, and completions).
- You can adjust model parameters (e.g. temperature) in the prompt playground.
- You can publicly share experiments (e.g. Alpaca Evals).
- Datasets now support editing, deleting, adding, and copying rows in the UI.
- There is no longer a 64KB limit on strings.
Week of 2023-08-28
- The prompt playground is now live! We're excited to get your feedback as we continue to build this feature out. See the docs for more information.
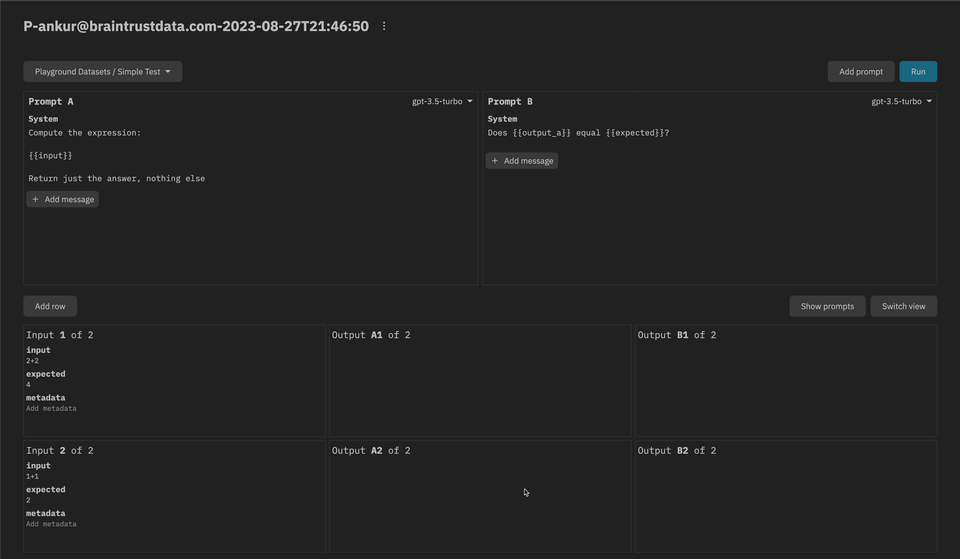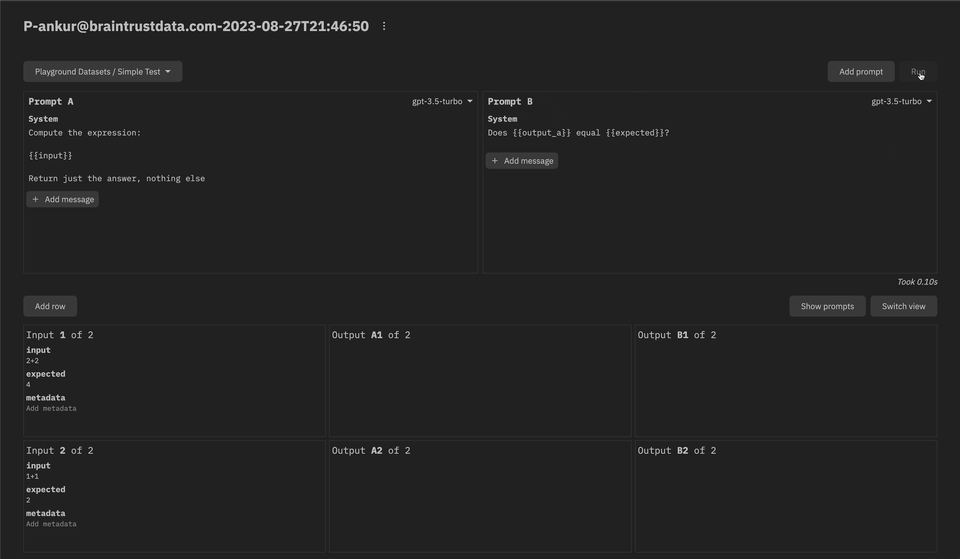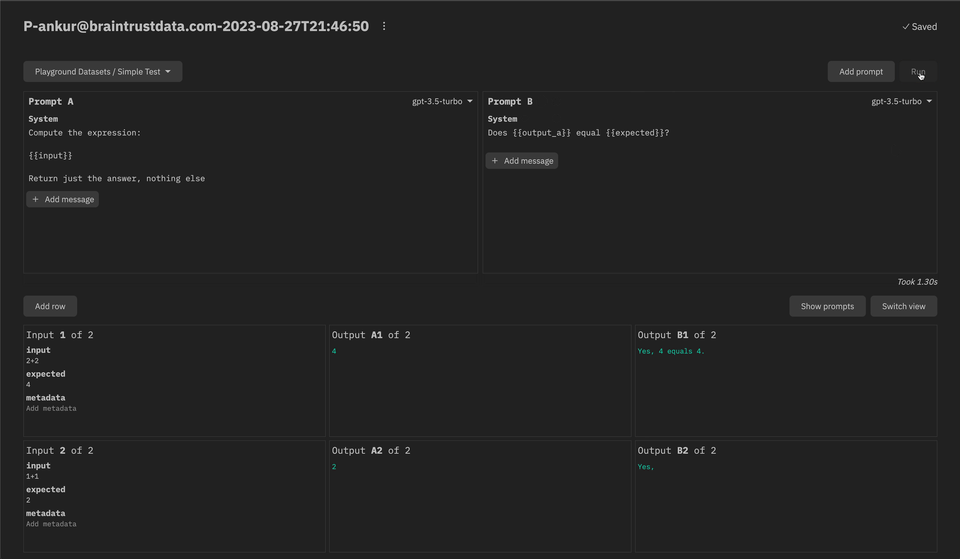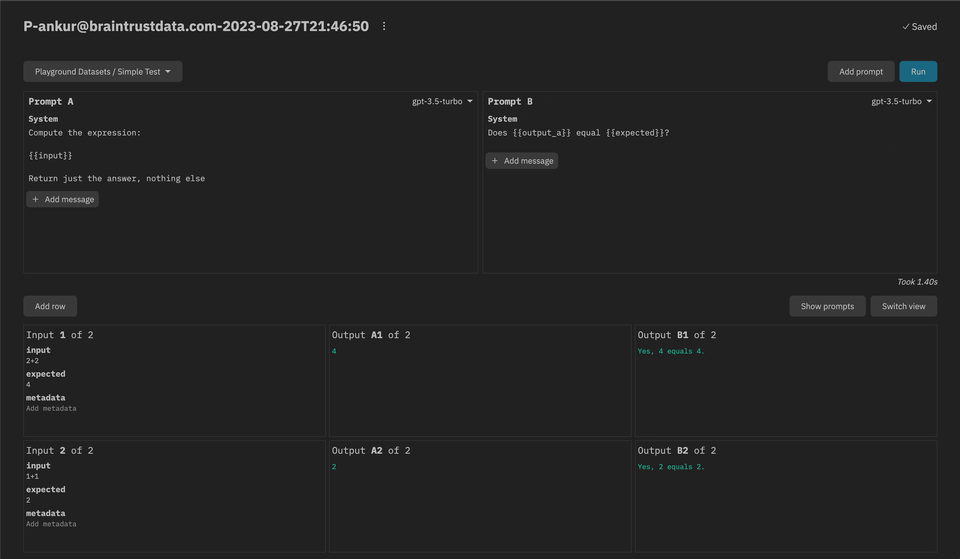
Week of 2023-08-21
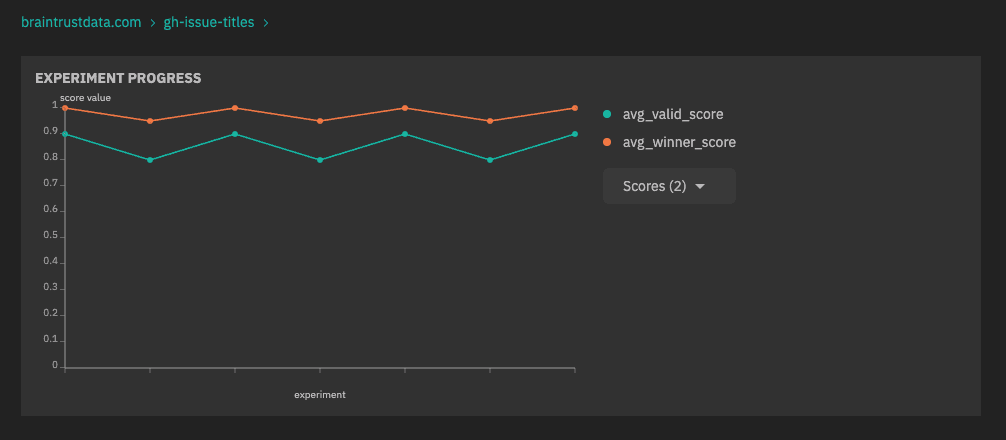
- A new chart shows experiment progress per score over time.
- The eval CLI now supports
--watch, which will automatically re-run your evaluation when you make changes to your code. - You can now edit datasets in the UI.

Week of 2023-08-14
- Introducing datasets! You can now upload datasets to Braintrust and use them in your experiments. Datasets are versioned, and you can use them in multiple experiments. You can also use datasets to compare your model's performance against a baseline. Learn more about how to create and use datasets in the docs.
- Fix several performance issues in the SDK and UI.
Week of 2023-08-07
- Complex data is now substantially more performant in the UI. Prior to this change, we ran schema
inference over the entire
input,output,expected, andmetadatafields, which could result in complex structures that were slow and difficult to work with. Now, we simply treat these fields asJSONtypes. - The UI updates in real-time as new records are logged to experiments.
- Ergonomic improvements to the SDK and CLI:
- The JS library is now Isomorphic and supports both Node.js and the browser.
- The Evals CLI warns you when no files match the
.eval.[ts|js]pattern.
Week of 2023-07-31
- You can now break down scores by metadata fields:
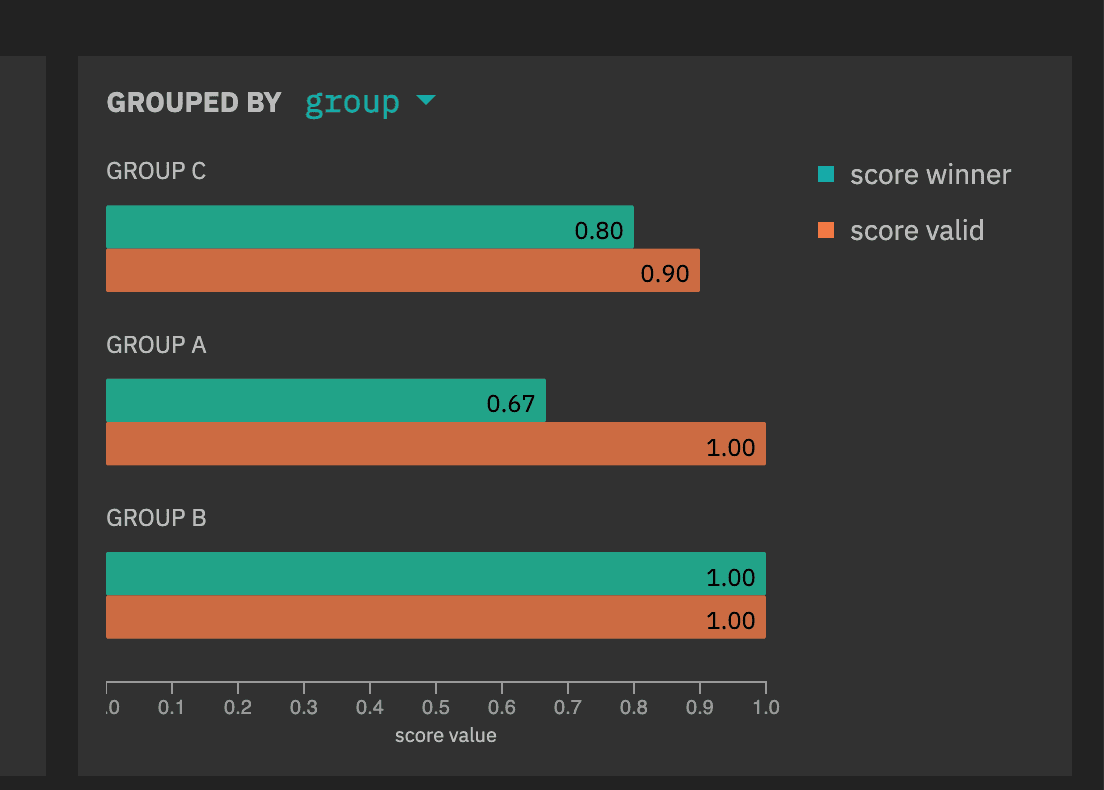
-
Improve performance for experiment loading (especially complex experiments). Prior to this change, you may have seen experiments take 30s+ occasionally or even fail. To enable this, you'll need to update your CloudFormation.
-
Support for renaming and deleting experiments:
- When you expand a cell in detail view, the row is now highlighted:
Week of 2023-07-24
- A new framework for expressing evaluations in a much simpler way:
import { Eval } from "braintrust";
import { Factuality } from "autoevals";
Eval("My Evaluation", {
data: () => [
{
input: "Which country has the highest population?",
expected: "China",
meta: { type: "question" },
},
],
task: (input) => callModel(input),
scores: [Factuality],
});Besides being much easier than the logging SDK, this framework sets the foundation for evaluations that can be run automatically as your code changes, built and run in the cloud, and more. We are very excited about the use cases it will open up!
inputsis nowinputin the SDK (>= 0.0.23) and UI. You do not need to make any code changes, although you should gradually start using theinputfield instead ofinputsin your SDK calls, asinputsis now deprecated and will eventually be removed.- Improved diffing behavior for nested arrays.
Week of 2023-07-17
- A couple of SDK updates (>= v0.0.21) that allow you to update an existing experiment
init(..., update=True)and specify an id inlog(..., id='my-custom-id'). These tools are useful for running an experiment across multiple processes, tasks, or machines, and idempotently logging the same record (identified by itsid).- Note: If you have Braintrust installed in your own cloud environment, make sure to update the CloudFormation (available at https://braintrust-cf.s3.amazonaws.com/braintrust-latest.yaml).
- Tables with lots and lots of columns are now visually more compact in the UI:
Before:
After:
Week of 2023-07-10
- A new Node.js SDK (npm) which mirrors the Python SDK. As this SDK is new, please let us know if you run into any issues or have any feedback.
If you have Braintrust installed in your own cloud environment, make sure to update the CloudFormation (available at https://braintrust-cf.s3.amazonaws.com/braintrust-latest.yaml) to include some functionality the Node.js SDK relies on.
You can do this in the AWS console, or by running the following command (with the braintrust command included in the Python SDK).
braintrust install api <YOUR_CLOUDFORMAT_STACK_NAME> --update-template- You can now swap the primary and comparison experiment with a single click.
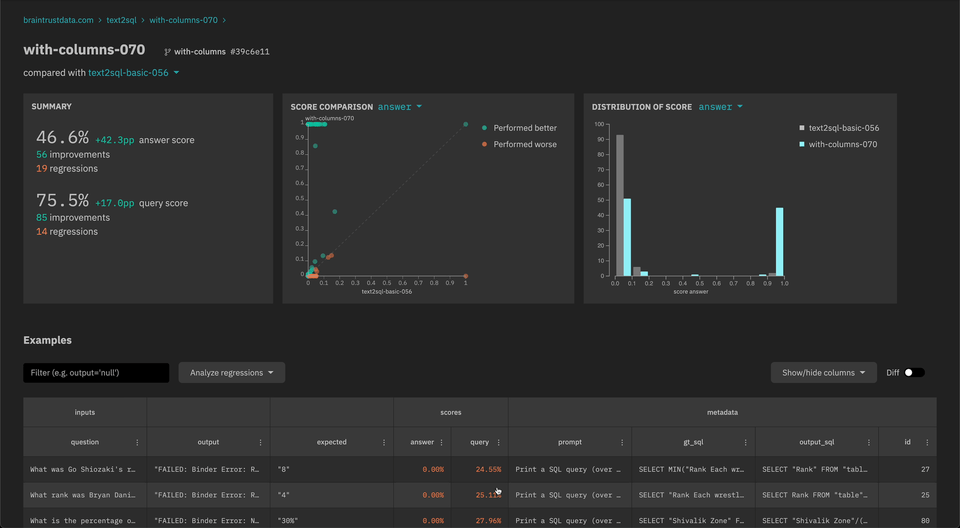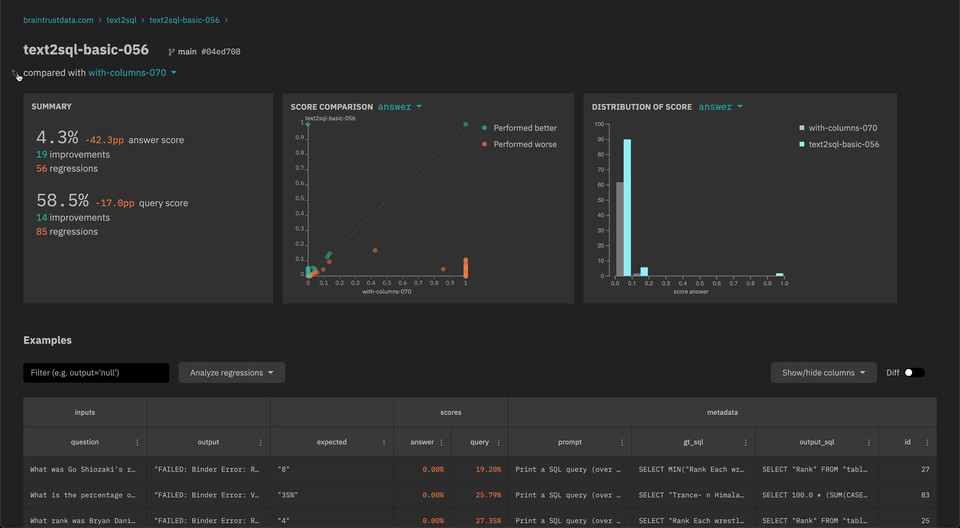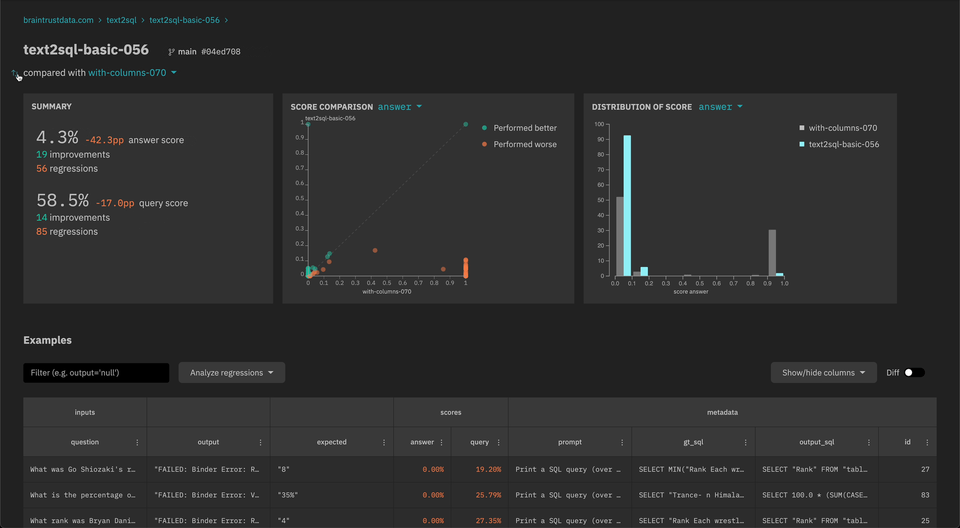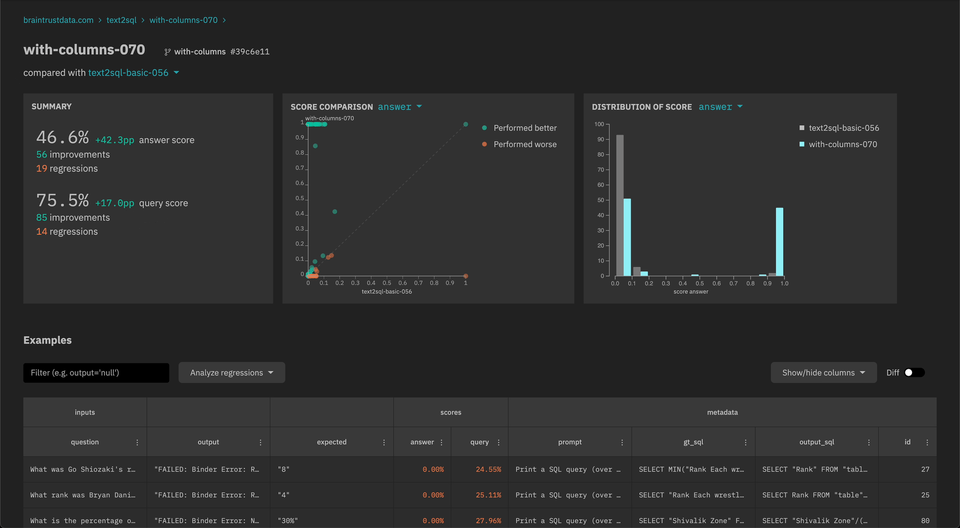
- You can now compare
outputvs.expectedwithin an experiment.

- Version 0.0.19 is out for the SDK. It is an important update that throws an error if your payload is larger than 64KB in size.
Week of 2023-07-03
-
Support for real-time updates, using Redis. Prior to this, Braintrust would wait for your data warehouse to sync up with Kafka before you could view an experiment, often leading to a minute or two of time before a page loads. Now, we cache experiment records as your experiment is running, making experiments load instantly. To enable this, you'll need to update your CloudFormation.
-
New settings page that consolidates team, installation, and API key settings. You can now invite team members to your Braintrust account from the "Team" page.
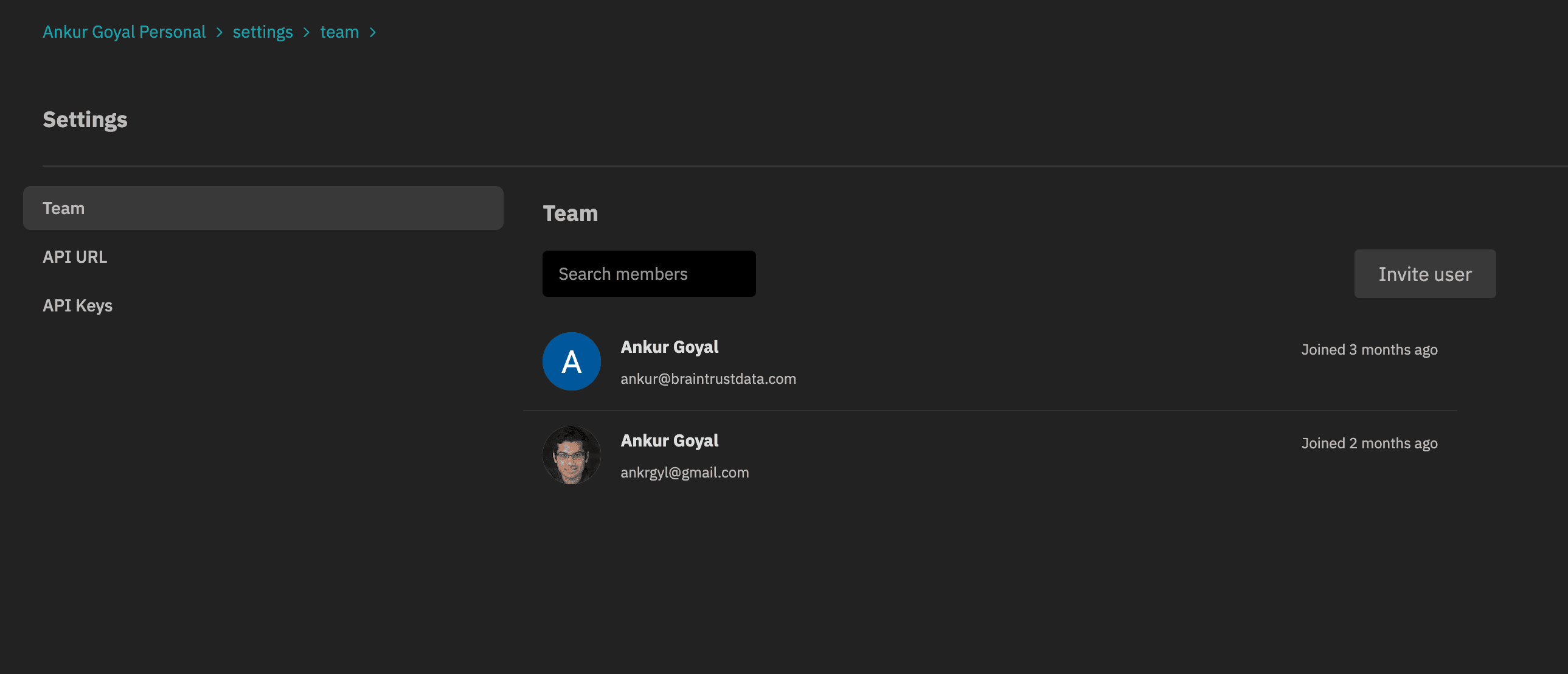
-
The experiment page now shows commit information for experiments run inside of a git repository.
Week of 2023-06-26
- Experiments track their git metadata and automatically find a "base" experiment to compare against, using your repository's base branch.
- The Python SDK's
summarize()method now returns anExperimentSummaryobject with score differences against the base experiment (v0.0.10). - Organizations can now be "multi-tenant", i.e. you do not need to install in your cloud account. If you start with a multi-tenant account to try out Braintrust, and decide to move it into your own account, Braintrust can migrate it for you.
Week of 2023-06-19
-
New scatter plot and histogram insights to quickly analyze scores and filter down examples.
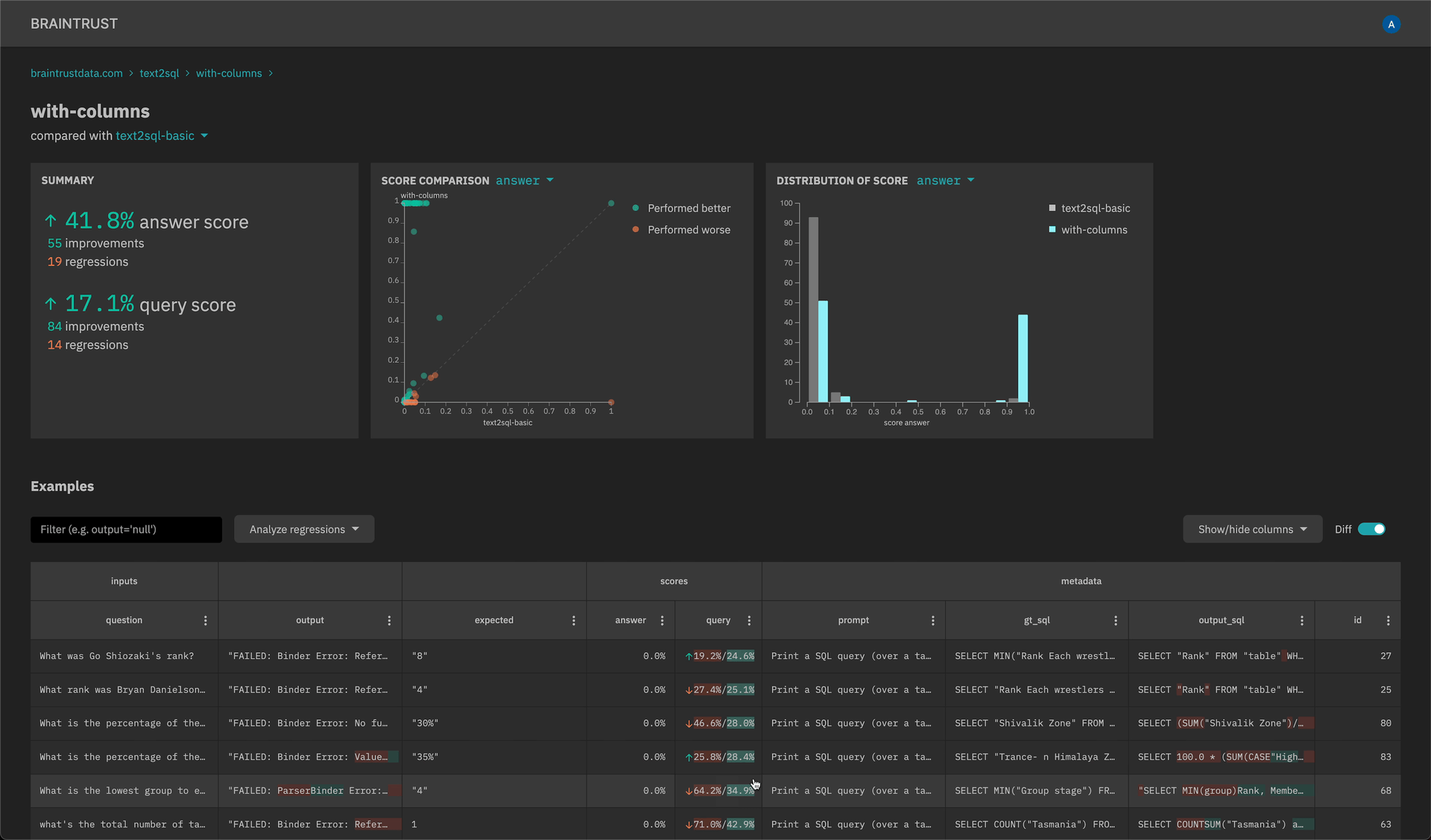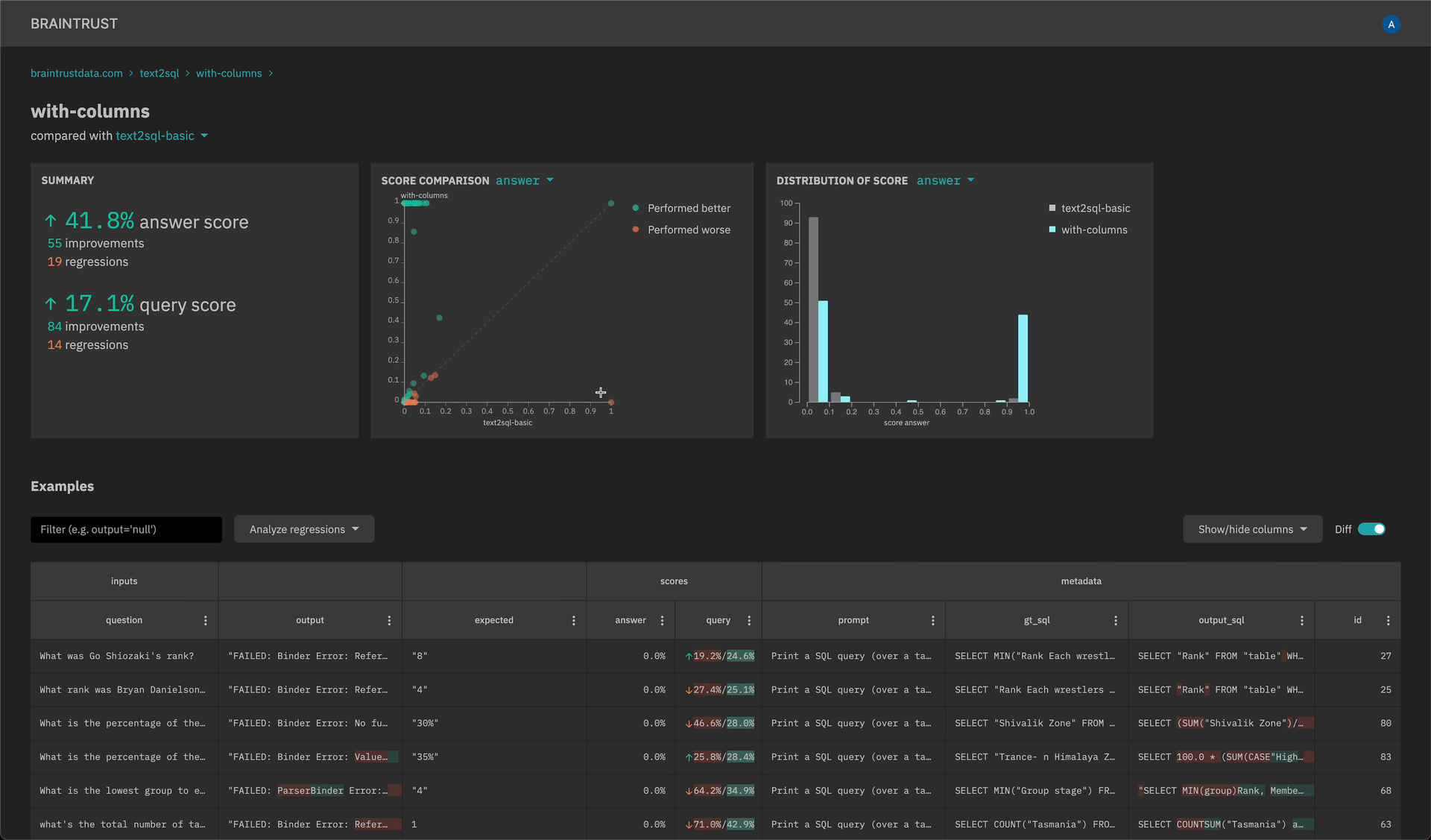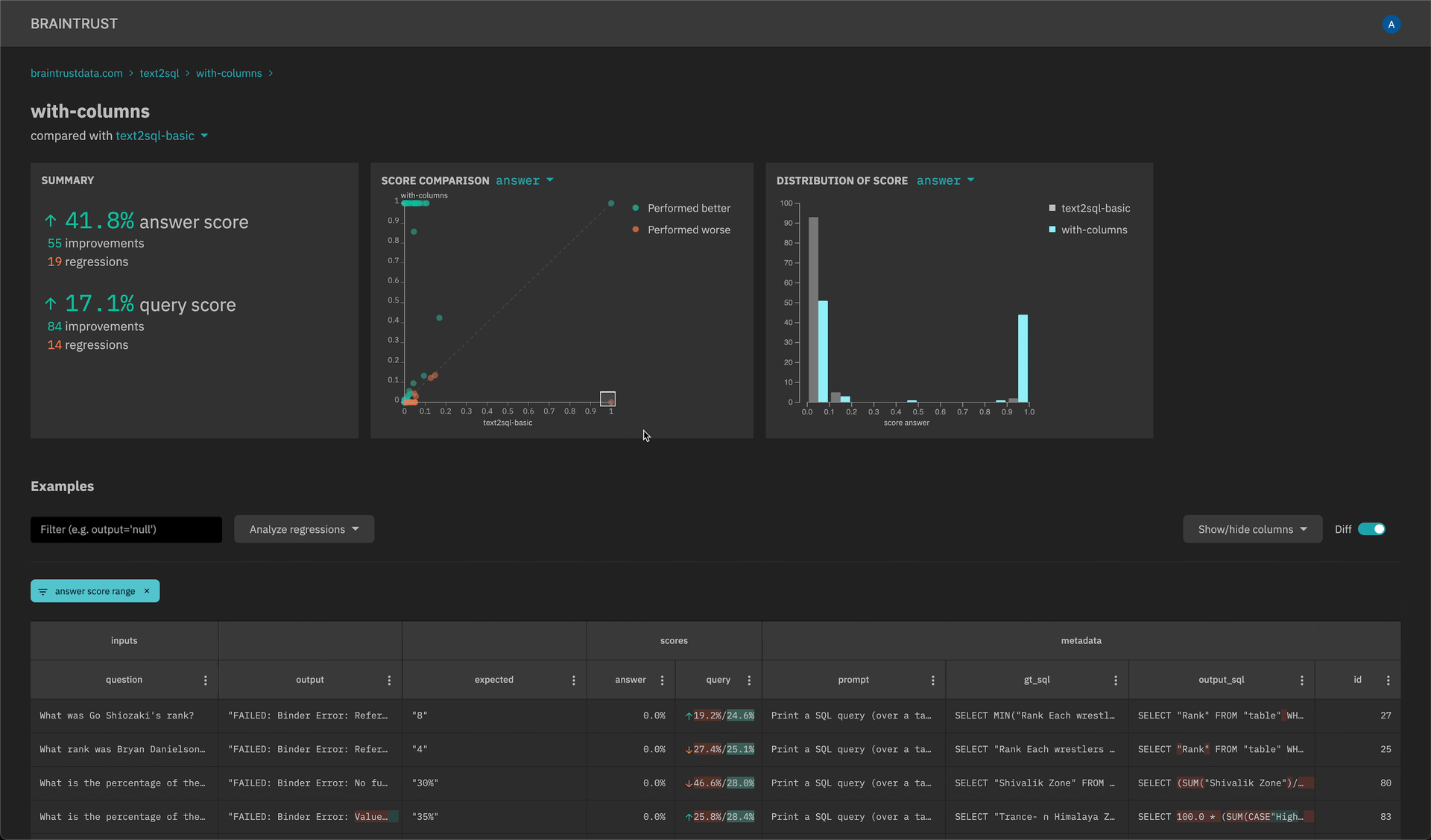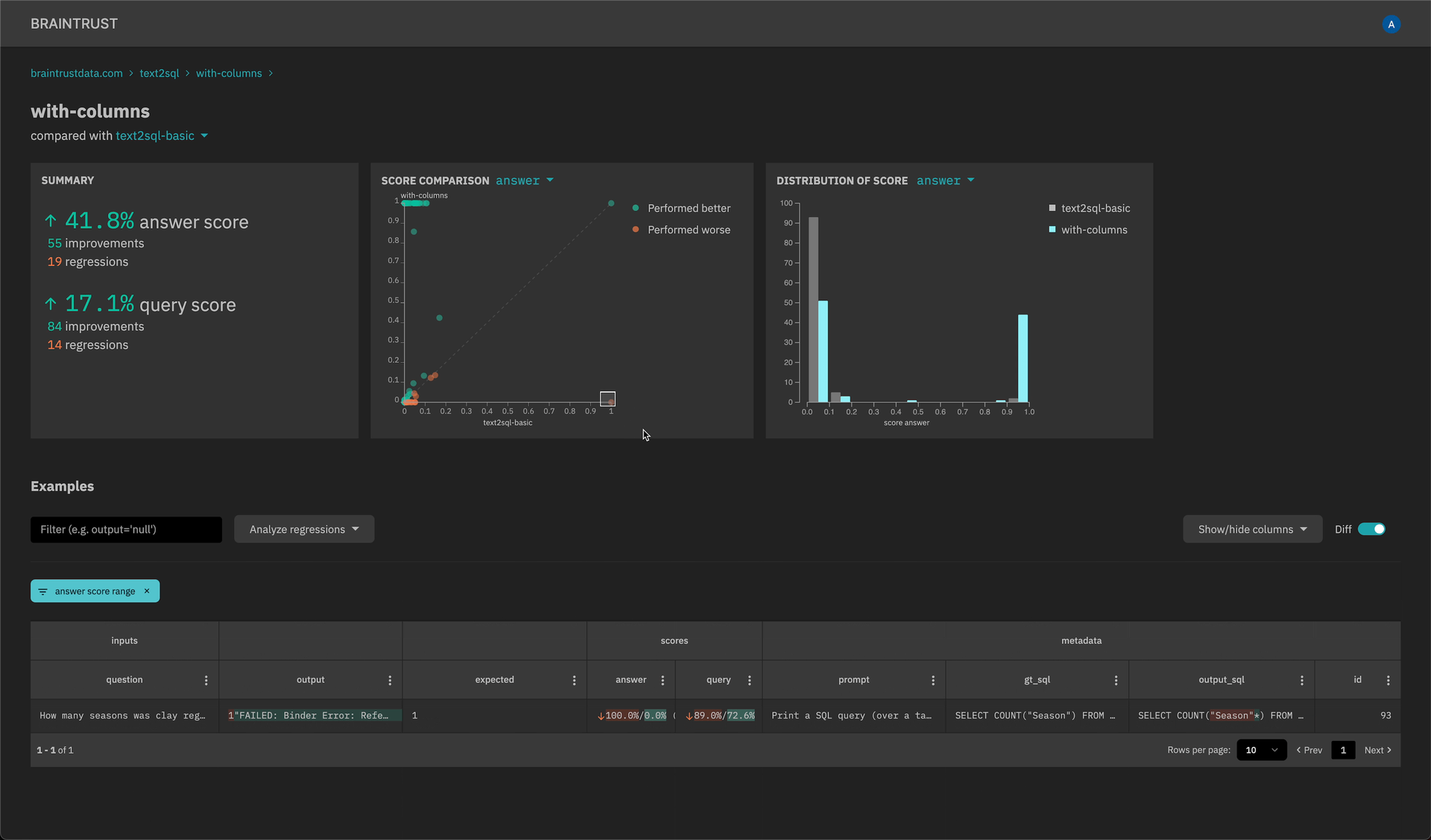
-
API keys that can be set in the SDK (explicitly or through an environment variable) and do not require user login. Visit the settings page to create an API key.
- Update the braintrust Python SDK to version 0.0.6 and the CloudFormation template (https://braintrust-cf.s3.amazonaws.com/braintrust-latest.yaml) to use the new API key feature.
Week of 2023-06-12
- New
braintrust installCLI for installing the CloudFormation - Improved performance for event logging in the SDK
- Auto-merge experiment fields with different types (e.g.
numberandstring)
Week of 2023-06-05
-
Automatically refresh cognito tokens in the Python client
-
New filter and sort operators on the experiments table:
- Filter experiments by changes to scores (e.g. only examples with a lower score than another experiment)
- Custom SQL filters
- Filter and sort bubbles to visualize/clear current operations
-
[Alpha] SQL query explorer to run arbitrary queries against one or more experiments
