Tracing
This guide walks through how to trace your code in Braintrust. Tracing is an invaluable tool for exploring the sub-components of your program which produce each top-level input and output. We currently support tracing in logging and evaluations.
Before proceeding, make sure to read the quickstart guide and setup an API key.
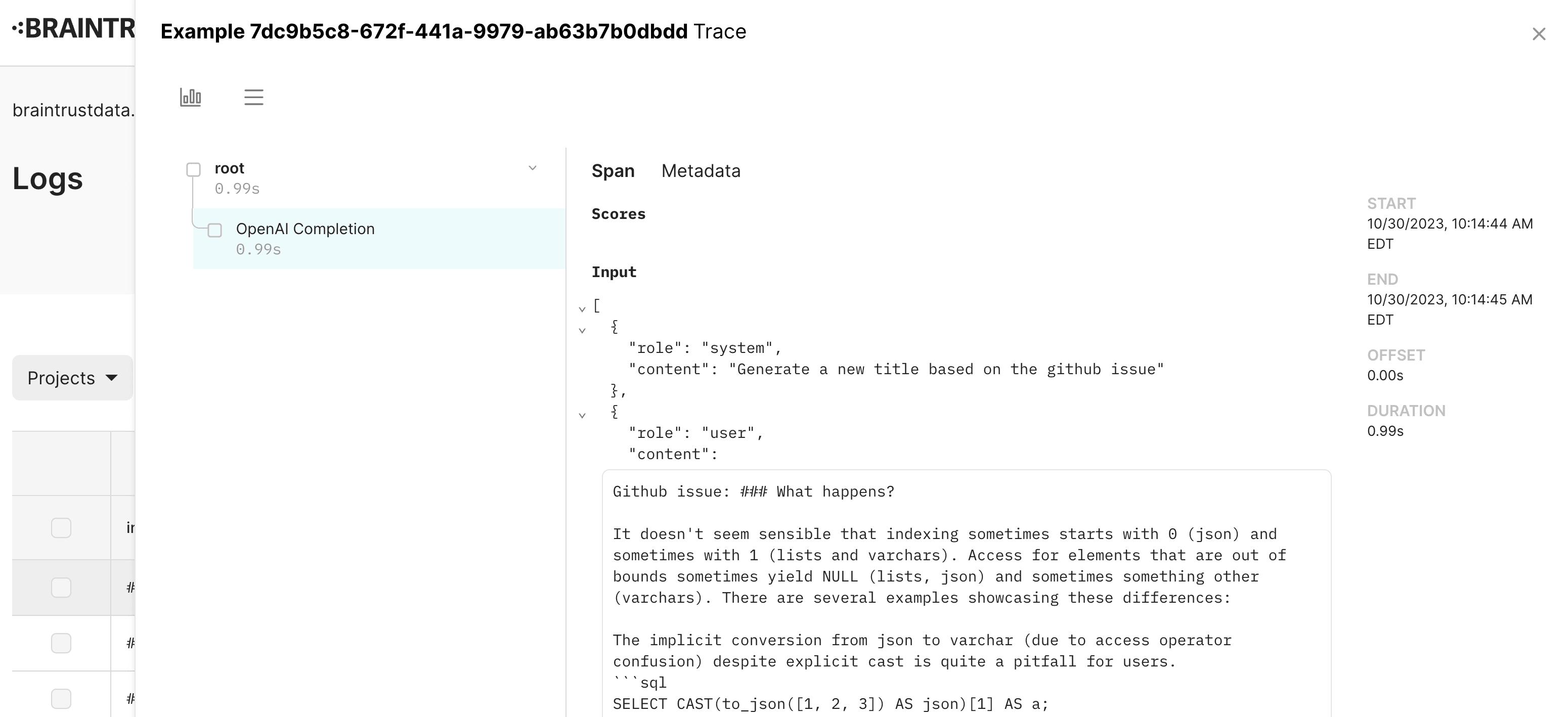
Traces: the building block of logs
The core building blocks of logging are spans and traces. A span represents a unit of work, with a start and end time, and optional fields like input, output, metadata, scores, and metrics (the same fields you can log in an Experiment). Each span contains one or more children, which are usually run within their parent span (e.g. a nested function call). Common examples of spans include LLM calls, vector searches, the steps of an agent chain, and model evaluations.
Together, spans form a trace, which represents a single independent request. Each trace is visible as a row in the final table. Well-designed traces make it easy to understand the flow of your application, and to debug issues when they arise. The rest of this guide walks through how to log rich, helpful traces. The tracing API works the same way whether you are logging online (production logging) or offline (evaluations), so the examples below apply to either use-case.
Annotating your code
To log a trace, you simply wrap the code you want to trace. Braintrust will automatically capture and log information behind the scenes.
import { initLogger, traced } from "braintrust";
const logger = initLogger({
projectName: "My Project",
apiKey: process.env.BRAINTRUST_API_KEY,
});
function preparePrompt(body: string) {
return traced(async (span) => {
const prompt = [
{ role: "system", content: "You are a helpful assistant." },
{ role: "user", content: body },
];
span.log({ input: body, output: prompt });
return prompt;
});
}
async function someLLMFunction(prompt: Record<string, string>) {
return traced(async (span) => {
const content = await invokeLLM(prompt).content;
span.log({ input: prompt, output: content });
return content;
});
}
export async function POST(req: Request) {
return traced(async (span) => {
const result = await someLLMFunction(preparePrompt(req.body));
span.log({ input: req.body, output: result });
return result;
});
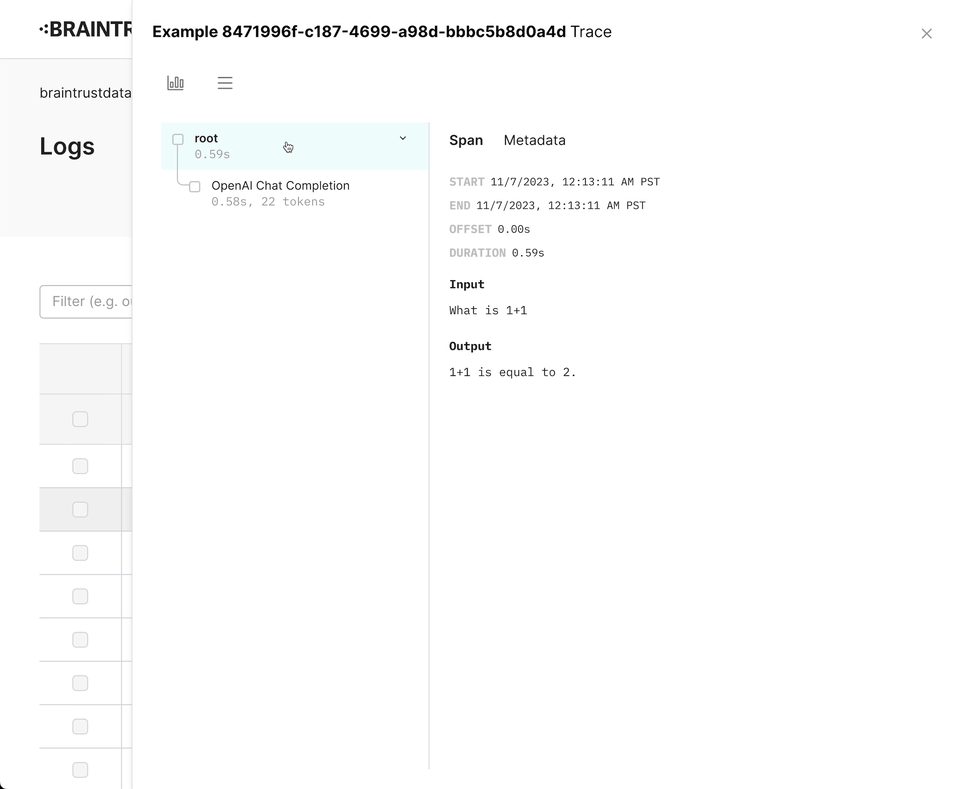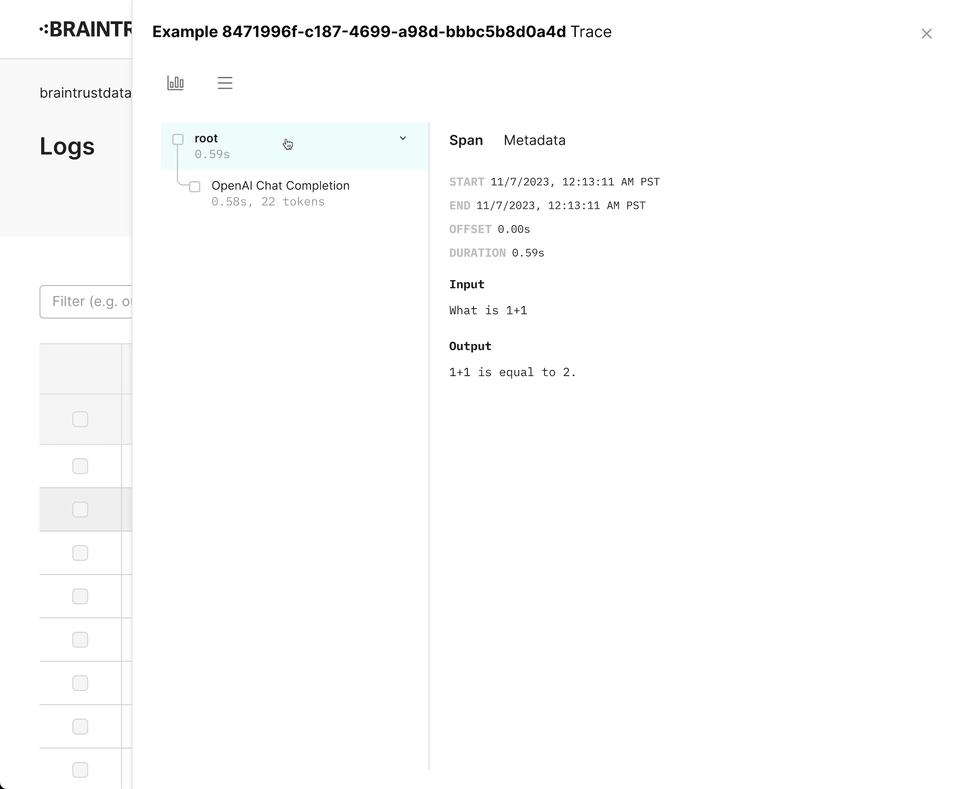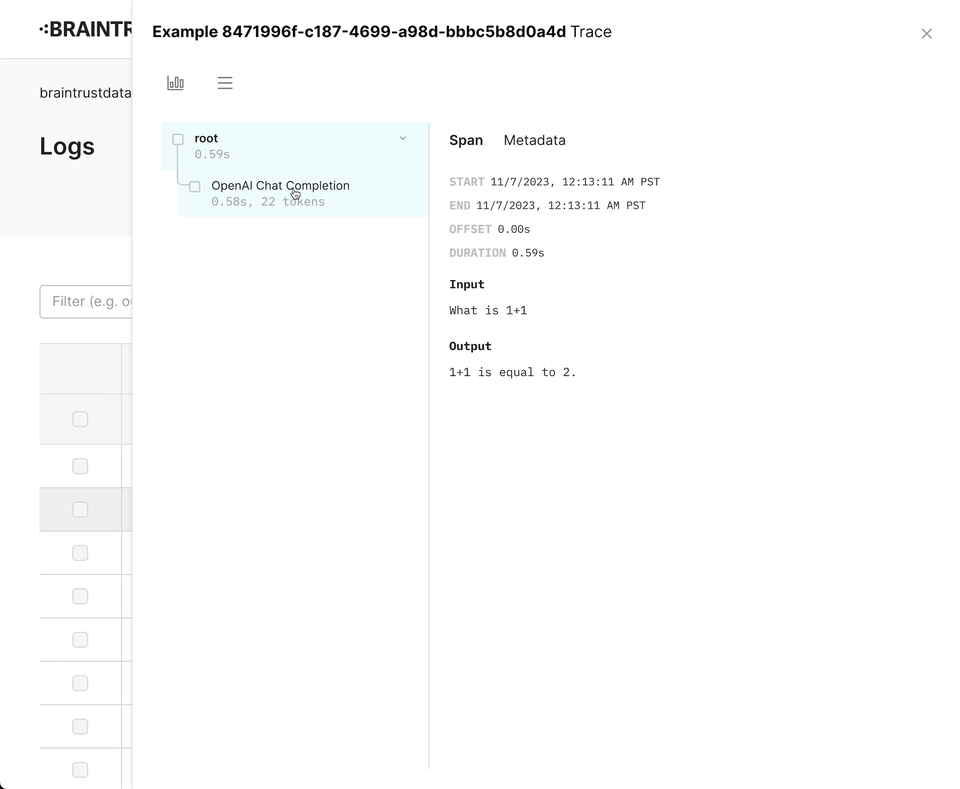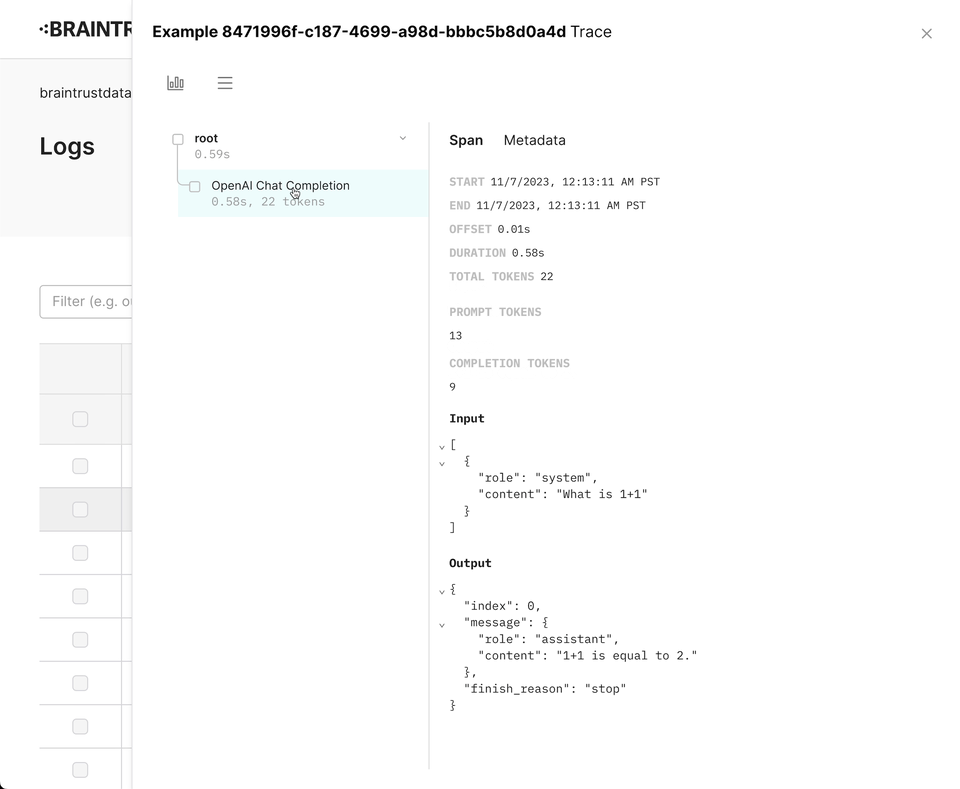
}Wrapping OpenAI
Braintrust includes a wrapper for the OpenAI API that automatically logs your
requests. To use it, simply call wrapOpenAI/wrap_openai on your OpenAI
instance. We intentionally do not monkey
patch the libraries directly, so
that you can use the wrapper in a granular way.
import { OpenAI } from "openai";
import { initLogger, traced, wrapOpenAI } from "braintrust";
const client = wrapOpenAI(new OpenAI());
const logger = initLogger({
projectName: "My Project",
apiKey: process.env.BRAINTRUST_API_KEY,
});
async function someLLMFunction(body: string) {
return traced(async (span) => {
const result = await client.chat.completions.create({
model: "gpt-3.5-turbo",
messages: [{ role: "user", content: req.body }],
});
const content = result.choices[0]?.message.content;
span.log({ input: prompt, output: content });
return content;
});
}
export async function POST(req: Request) {
return traced(async (span) => {
const result = await someLLMFunction(req.body);
span.log({
input: req.body,
output: result,
metadata: { user_id: req.user.id },
});
return result;
});
}
Wrapping a custom LLM client
It is of course possible to wrap your own LLM client using braintrust. Similar to the previous example:
import { initLogger, traced } from "braintrust";
const logger = initLogger({
projectName: "My Project",
apiKey: process.env.BRAINTRUST_API_KEY,
});
async function invokeCustomLLM(llmInput) {
return traced(async (span) => {
const result = await callMyLLM(input);
const content = result.completion;
span.log({
input: llmInput.body,
output: content,
metrics: { tokens: result.tokens },
metadata: llmInput.params,
});
return content;
});
}
export async function POST(req: Request) {
return traced(async (span) => {
const result = await invokeCustomLLM({
body: req.body,
params: { temperature: 0.1 },
});
span.log({ input: req.body, output: result });
return result;
});
}Deeply nested code
Often, you want to trace functions that are deep in the call stack, without
having to propagate the span object throughout. Braintrust uses async-friendly
context variables to make this workflow easy:
- The
tracedfunction/decorator will create a span underneath the currently-active span. - The
currentSpan()/current_span()method returns the currently active span, in case you need to do additional logging.
import { currentSpan, initLogger, traced } from "braintrust";
const logger = initLogger();
export async function runLLM(input) {
return await traced(async () => {
const result = await someLLMFunction(input);
const output = result.content;
currentSpan().log({
input,
output,
metrics: {
tokens: result.tokens,
},
});
return output;
});
}
export async function someLogic(input: string) {
return traced(async () => {
const result = await runLLM("You are a magical wizard. Answer the following question: " + input);
currentSpan().log({input: input; output: result});
return result;
});
}
export async function POST(req) {
return await traced(async () {
const result = await someLogic(req.body);
currentSpan().log({input: req.body, output: result, metadata: {user_id: req.user.id}});
return result;
});
}Tracing integrations
Langchain
To trace Langchain code in Braintrust, you can use the BraintrustTracer callback handler. The callback
handler is currently only supported in Python, but if you need support for other languages, please
let us know.
To use it, simply initialize a BraintrustTracer and pass it as a callback handler to langchain objects
you create.
from braintrust import Eval
from braintrust.wrappers.langchain import BraintrustTracer
from langchain.chains import LLMMathChain
from langchain.chat_models import ChatOpenAI
from autoevals import Levenshtein
tracer = BraintrustTracer()
llm = ChatOpenAI(model="gpt-3.5-turbo", callbacks=[tracer])
llm_math = LLMMathChain.from_llm(llm, callbacks=[tracer])
Eval(
"Calculator",
data=[{"input": "1+1", "expected": "2"}],
task=lambda input: llm_math.invoke(input),
scores=[Levenshtein],
)Manually managing spans
In more complicated environments, it may not always be possible to wrap the entire duration of a span within a single block of code. In such cases, you can always pass spans around manually.
Consider this hypothetical server handler, which logs to a span incrementally over several distinct callbacks:
import {
Span,
init,
startSpan,
traced,
} from "braintrust";
function computeOutput(systemPrompt: string, userInput: string, parentSpan: Span) {
return parentSpan.traced(async (span) => {
const input = {messages: [
{ role: "system", text: systemPrompt },
{ role: "user", text: userInput },
]};
const output = await computeOutputImpl(input);
span.log({input, output});
return output;
});
}
class MyHandler {
private liveSpans: Record<string, { span: Span; input: string }>;
constructor() {
this.liveSpans = {};
}
async onRequestStart(requestId, input, expected) {
const span = startSpan({name: requestId, event: {input, expected}});
this.liveSpans[requestId] = { span, input };
}
async onGetOutput(requestId, systemPrompt) {
const { span, input } = this.liveSpans[requestId];
const output = await computeOutput(systemPrompt, input, span);
span.log({output});
}
async onRequestEnd(requestId, metadata) {
{ span } = this.liveSpans[requestId];
delete this.liveSpans[requestId];
span.log({metadata});
span.end();
}
}
experiment = init("My long-running experiment");
server.runForever(new MyHandler());Importing and exporting spans
Spans are processed in Braintrust as a simple format, consisting of input, output, expected, metadata, scores,
and metrics fields (all optional), as well as a few system-defined fields which you usually do not need to mess with, but
are described below for completeness. This simple format makes
it easy to import spans captured in other systems (e.g. languages other than Typescript/Python), or to export spans from
Braintrust to consume in other systems.
Underlying format
The underlying span format contains a number of fields which are not exposed directly through the SDK, but are useful to understand when importing/exporting spans.
idis a unique identifier for the span, within the container (e.g. an experiment, or logs for a project). You can technically set this field yourself (to overwrite a span), but it is recommended to let Braintrust generate it automatically.input,output,expected,scores,metadata, andmetricsare optional fields which describe the span and are exposed in the Braintrust UI. When you use the Typescript or Python SDK, these fields are validated for you (e.g. scores must be a mapping from strings to numbers between 0 and 1).span_attributescontains attributes about the span. Currently the recognized attributes arename, which is used to display the span name in the UI, andtype, which displays a helpful icon.typeshould be one of"llm","score","function","eval","task", or"tool".- Depending on the container, e.g. an experiment, or project logs, or a dataset, fields like
project_id,experiment_id,dataset_id, andlog_idare set automatically, by the SDK, so the span can be later retrieved by the UI and API. You should not set these fields yourself. span_id,root_span_id, andspan_parentsare used to construct the span tree and are automatically set by Braintrust. You should not set these fields yourself, but rather let the SDK create and manage them (even if importing from another system).
When importing spans, the only fields you should need to think about are input, output, expected, scores, metadata, and metrics.
You can use the SDK to populate the remaining fields, which the next section covers with an example.
Here is an example of a span in the underlying format:
{
"id": "385052b6-50a2-43b4-b52d-9afaa34f0bff",
"input": {
"question": "What is the origin of the customer support issue??"
},
"output": {
"answer": "The customer support issue originated from a bug in the code.",
"sources": ["http://www.example.com/faq/1234"]
},
"expected": {
"answer": "Bug in the code that involved dividing by zero.",
"sources": ["http://www.example.com/faq/1234"]
},
"scores": {
"Factuality": 0.6
},
"metadata": {
"pos": 1
},
"metrics": {
"end": 1704872988.726753,
"start": 1704872988.725727
// Can also include `tokens`, etc. here
},
"project_id": "d709efc0-ac9f-410d-8387-345e1e5074dc",
"experiment_id": "51047341-2cea-4a8a-a0ad-3000f4a94a96",
"created": "2024-01-10T07:49:48.725731+00:00",
"span_id": "70b04fd2-0177-47a9-a70b-e32ca43db131",
"root_span_id": "68b4ef73-f898-4756-b806-3bdd2d1cf3a1",
"span_parents": ["68b4ef73-f898-4756-b806-3bdd2d1cf3a1"],
"span_attributes": {
"name": "doc_included"
}
}Example import/export
The following example walks through how to generate spans in one program and then import them to Braintrust in a script. You can use this pattern to support tracing or running experiments in environments that use programming languages other than Typescript/Python (e.g. Kotlin, Java, Go, Ruby, Rust, C++), or codebases that cannot integrate the Braintrust SDK directly.
Generating spans
The following example runs a simple LLM app and collects logging information at each stage of the process, without using the Braintrust SDK. This could be implemented in any programming language, and you certainly do not need to collect or process information this way. All that matters is that your program generates a useful format that you can later parse and use to import the spans using the SDK.
import json
import time
import openai
client = openai.OpenAI()
def run_llm(input, **params):
start = time.time()
messages = [{"role": "user", "content": input}]
result = client.chat.completions.create(
model="gpt-3.5-turbo", messages=[{"role": "user", "content": input}], **params
)
end = time.time()
return {
"input": messages,
"output": result.choices[0].message.dict(),
"metadata": {"model": "gpt-3.5-turbo", "params": params},
"metrics": {
"start": start,
"end": end,
"tokens": result.usage.total_tokens,
"prompt_tokens": result.usage.prompt_tokens,
"completion_tokens": result.usage.completion_tokens,
},
"name": "OpenAI Chat Completion",
}
PROMPT_TEMPLATE = "Answer the following question: %s"
def run_input(question, expected):
result = run_llm(PROMPT_TEMPLATE % question, max_tokens=32)
return {
"input": question,
"output": result["output"]["content"],
# Expected is propagated here to make it easy to use it in the import
# script, but it's not strictly needed to be here.
"expected": expected,
"metadata": {
"template": PROMPT_TEMPLATE,
},
"children": [result],
"name": "run_input",
}
if __name__ == "__main__":
for question, expected in [
[
"What is 1+1?",
"2.",
],
[
"Which is larger, the sun or the moon?",
"The sun.",
],
]:
print(json.dumps(run_input(question, expected)))
Running this script produces output like:
{"input": "What is 1+1?", "output": "The sum of 1+1 is 2.", "expected": "2.", "metadata": {"template": "Answer the following question: %s"}, "children": [{"input": [{"role": "user", "content": "Answer the following question: What is 1+1?"}], "output": {"content": "The sum of 1+1 is 2.", "role": "assistant", "function_call": null, "tool_calls": null}, "metadata": {"model": "gpt-3.5-turbo", "params": {"max_tokens": 32}}, "metrics": {"start": 1704916642.978631, "end": 1704916643.450115, "tokens": 30, "prompt_tokens": 19, "completion_tokens": 11}, "name": "OpenAI Chat Completion"}], "name": "run_input"}
{"input": "Which is larger, the sun or the moon?", "output": "The sun is larger than the moon.", "expected": "The sun.", "metadata": {"template": "Answer the following question: %s"}, "children": [{"input": [{"role": "user", "content": "Answer the following question: Which is larger, the sun or the moon?"}], "output": {"content": "The sun is larger than the moon.", "role": "assistant", "function_call": null, "tool_calls": null}, "metadata": {"model": "gpt-3.5-turbo", "params": {"max_tokens": 32}}, "metrics": {"start": 1704916643.450675, "end": 1704916643.839096, "tokens": 30, "prompt_tokens": 22, "completion_tokens": 8}, "name": "OpenAI Chat Completion"}], "name": "run_input"}Importing spans
The following program uses the Braintrust SDK in Python to import the spans generated by the previous script. Again, you can modify this program to fit the needs of your environment, e.g. to import spans from a different source or format.
import json
import sys
import braintrust
from autoevals import Factuality
def upload_tree(span, node, **kwargs):
span.log(
input=node.get("input"),
output=node.get("output"),
expected=node.get("expected"),
metadata=node.get("metadata"),
metrics=node.get("metrics"),
**kwargs
)
for c in node.get("children", []):
with span.start_span(name=c.get("name")) as span:
upload_tree(span, c)
if __name__ == "__main__":
# This could be another container, like a log stream initialized
# via braintrust.init_logger()
experiment = braintrust.init("My Support App")
factuality = Factuality()
for line in sys.stdin:
tree = json.loads(line)
with experiment.start_span(name="task") as span:
upload_tree(span, tree)
with span.start_span(name="Factuality"):
score = factuality(input=tree["input"], output=tree["output"], expected=tree["expected"])
span.log(
scores={
"factuality": score.score,
},
# This will merge the metadata from the factuality score with the
# metadata from the tree.
metadata={"factuality": score.metadata},
)
print(experiment.summarize())Frequently asked questions
What happens if I annotate code but am not running an eval or logging?
If you are not running an eval or logging, then the tracing code will be a no-op with negligible performance overhead.
How do I trace from languages other than Typescript/Python?
You can use the Braintrust API to import spans from other languages. See the import/export section for details. We are also exploring support for other languages. Feel free to reach out if you have a specific request.
What are the limitations of the trace data structure? Can I trace a graph?
A trace is a directed acyclic graph (DAG) of spans. Each span can have multiple parents, but most executions are a tree of spans. Currently, the UI only supports displaying a single root span, due to the popularity of this pattern.