Logging
This guide walks through how to log real-world interactions in your application. We encourage you to use the feature to track user behavior, debug customer issues, and incorporate new patterns into your evaluations. Ultimately, logging effectively is a critical component to developing high quality AI applications.
Before proceeding, make sure to read the quickstart guide and setup an API key.
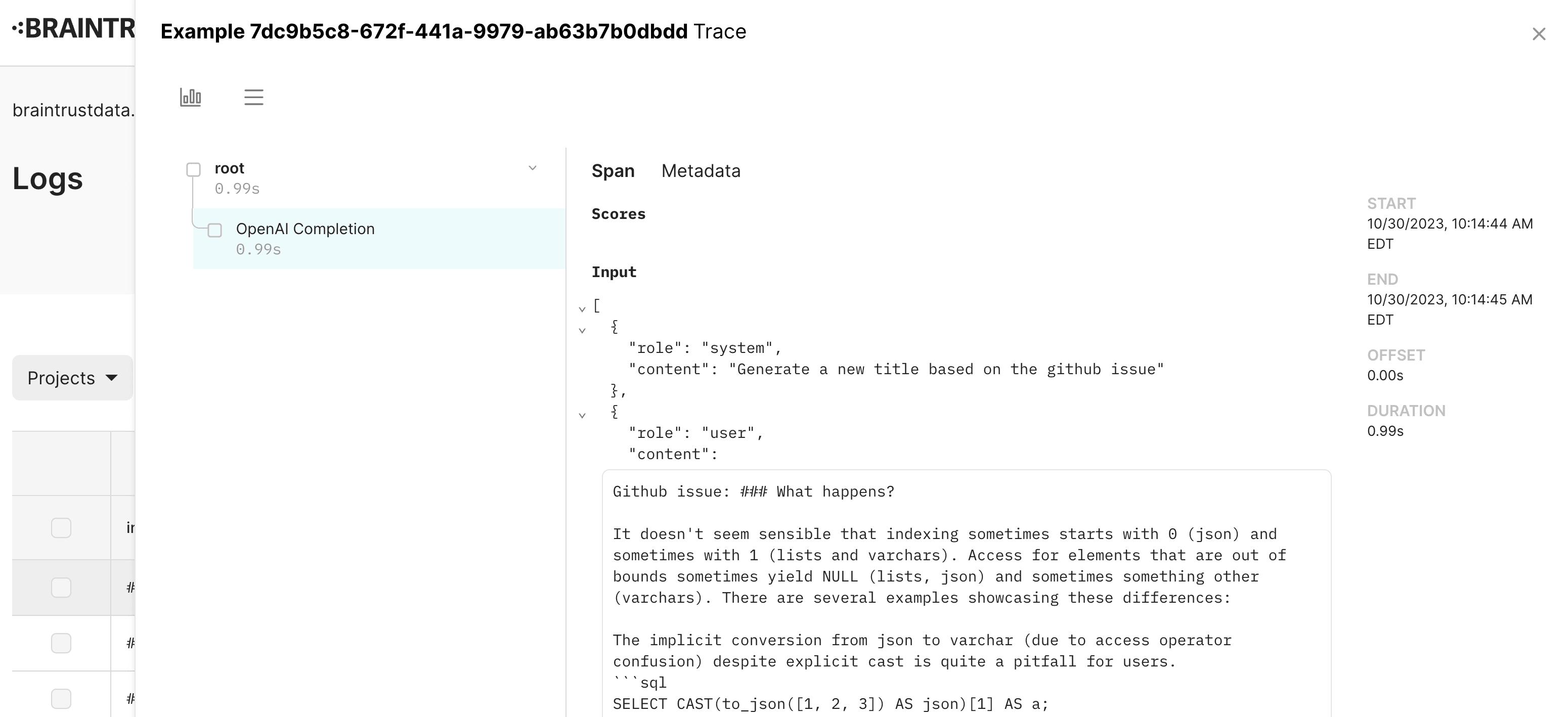
Writing logs
To write to braintrust, simply wrap the code you wish to log. Braintrust will automatically capture and log information behind the scenes.
import { initLogger, traced } from "braintrust";
const logger = initLogger({
projectName: "My Project",
apiKey: process.env.BRAINTRUST_API_KEY,
});
async function someLLMFunction(input: string) {
return traced(async (span) => {
const output = invokeLLM(input);
span.log({ input, output });
});
}
export async function POST(req: Request) {
return traced(async (span) => {
return await someLLMFunction(req.body);
});
}For full details, refer to the tracing guide, which describes how to log traces to braintrust.
Viewing logs
To view logs, navigate to the "Logs" tab in the appropriate project in the Braintrust UI. Logs are automatically updated in real-time as new traces are logged.
You can filter logs by time range or arbitrary subfields using DuckDB's expression syntax.
For example, to view all logs generated in the past day, add the created >= current_date - INTERVAL 1 DAY filter.
To search for logs with a specific metadata field, use the metadata.<field> syntax. For example, to search for logs with
a user_id field equal to 1234, add the metadata.user_id = '1234'.
User feedback
Braintrust supports logging user feedback, which can take multiple forms:
- A score for a specific span, e.g. the output of a request could be 👍 (corresponding to 1) or 👎 (corresponding to 0), or a document retrieved in a vector search might be marked as relevant or irrelevant on a scale of 0->1.
- An expected value, which gets saved in the
expectedfield of a span, alongsideinputandoutput. This is a great place to store corrections. - A comment, which is a free-form text field that can be used to provide additional context.
- Additional metadata fields, which allow you to track informationa about the feedback, like the
user_idorsession_id.
Each time you submit feedback, you can specify one or more of these fields using the logFeedback() / log_feedback() method, which
simply needs you to specify the span_id corresponding to the span you want to log feedback for, and the feedback fields you want to update.
The following example shows how to log feedback within a simple API endpoint.
import { initLogger } from "braintrust";
const logger = initLogger({
projectName: "My Project",
apiKey: process.env.BRAINTRUST_API_KEY,
});
export async function POST(req: Request) {
return logger.traced(async (span) => {
const { body } = req;
const result = await someLLMFunction(body);
span.log({ input: body, output: result });
return {
result,
requestId: span.id,
};
});
}
export async function POSTFeedback(req: Request) {
logger.logFeedback({
id: req.body.spanId,
scores: {
correctness: req.body.score,
},
comment: req.body.comment,
metadata: {
user_id: req.user.id,
},
});
}Collecting multiple scores
Often, you want to collect multiple scores for a single span. For example, multiple users might provide independent feedback on
a single document. Although each score and expected value is logged separately, each update overwrites the previous value. Instead, to
capture multiple scores, you should create a new span for each submission, and log the score in the scores field. When you view
and use the trace, Braintrust will automatically average the scores for you in the parent span(s).
import { initLogger } from "braintrust";
logger = initLogger({
projectName: "My Project",
apiKey: process.env.BRAINTRUST_API_KEY,
});
export async function POST(req: Request) {
return logger.traced(async (span) => {
const { body } = req;
const result = await someLLMFunction(body);
span.log({ input: body, output: result });
return {
result,
requestId: span.span_id,
};
});
}
export async function POSTFeedback(req: Request) {
logger.traced(
async (span) => {
logger.logFeedback({
id: span.id, // Use the newly created span's id, instead of the original request's id
comment: req.body.comment,
scores: {
correctness: req.body.score,
},
metadata: {
user_id: req.user.id,
},
});
},
{
parentId: req.body.requestId,
name: "feedback",
}
);
}Tags and queues
Braintrust supports curating logs by adding tags, and then filtering on them in the UI. Tags naturally flow between logs, to datasets, and even to experiments, so you can use them to track various kinds of data across your application, and track how they change over time.
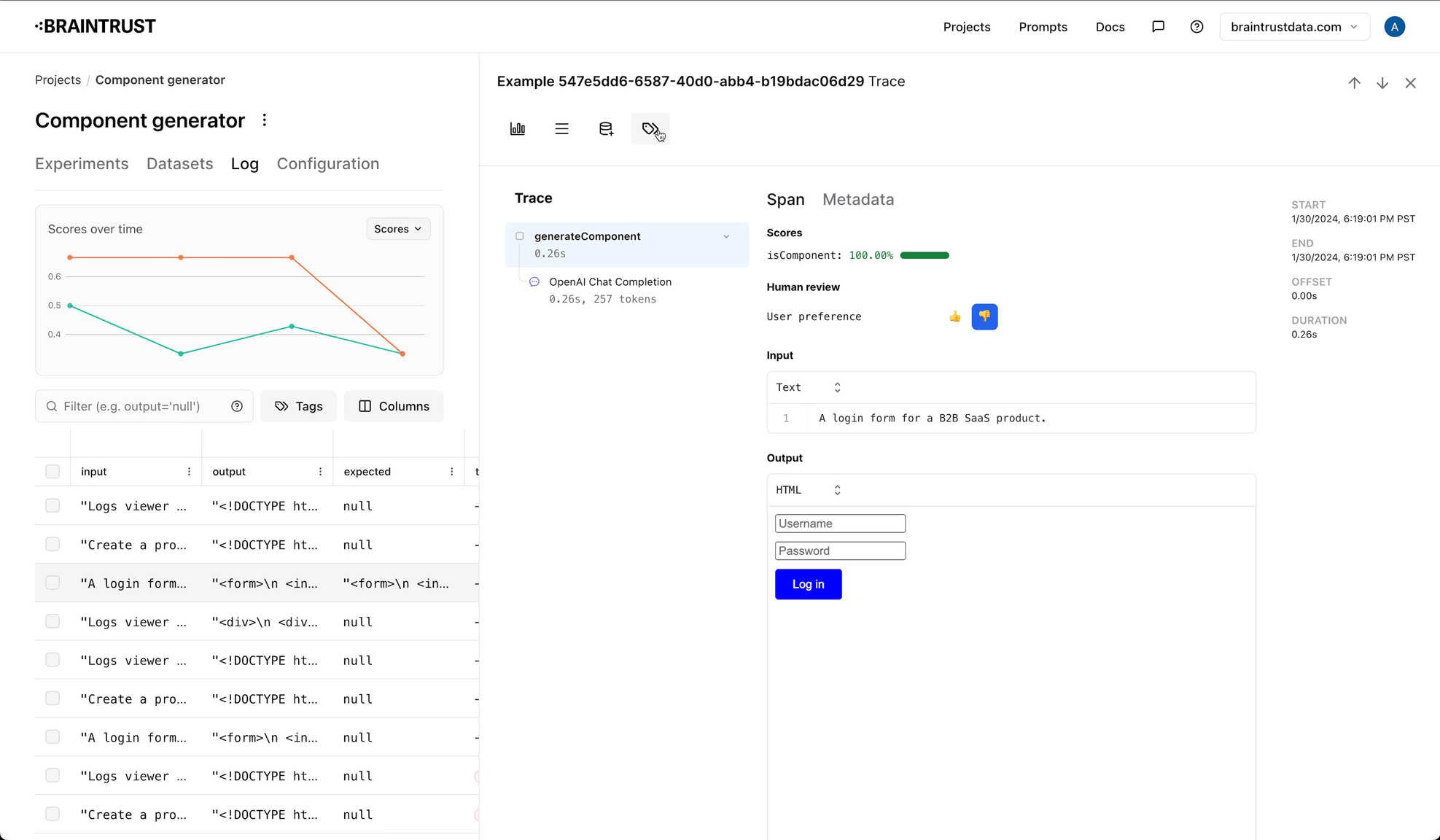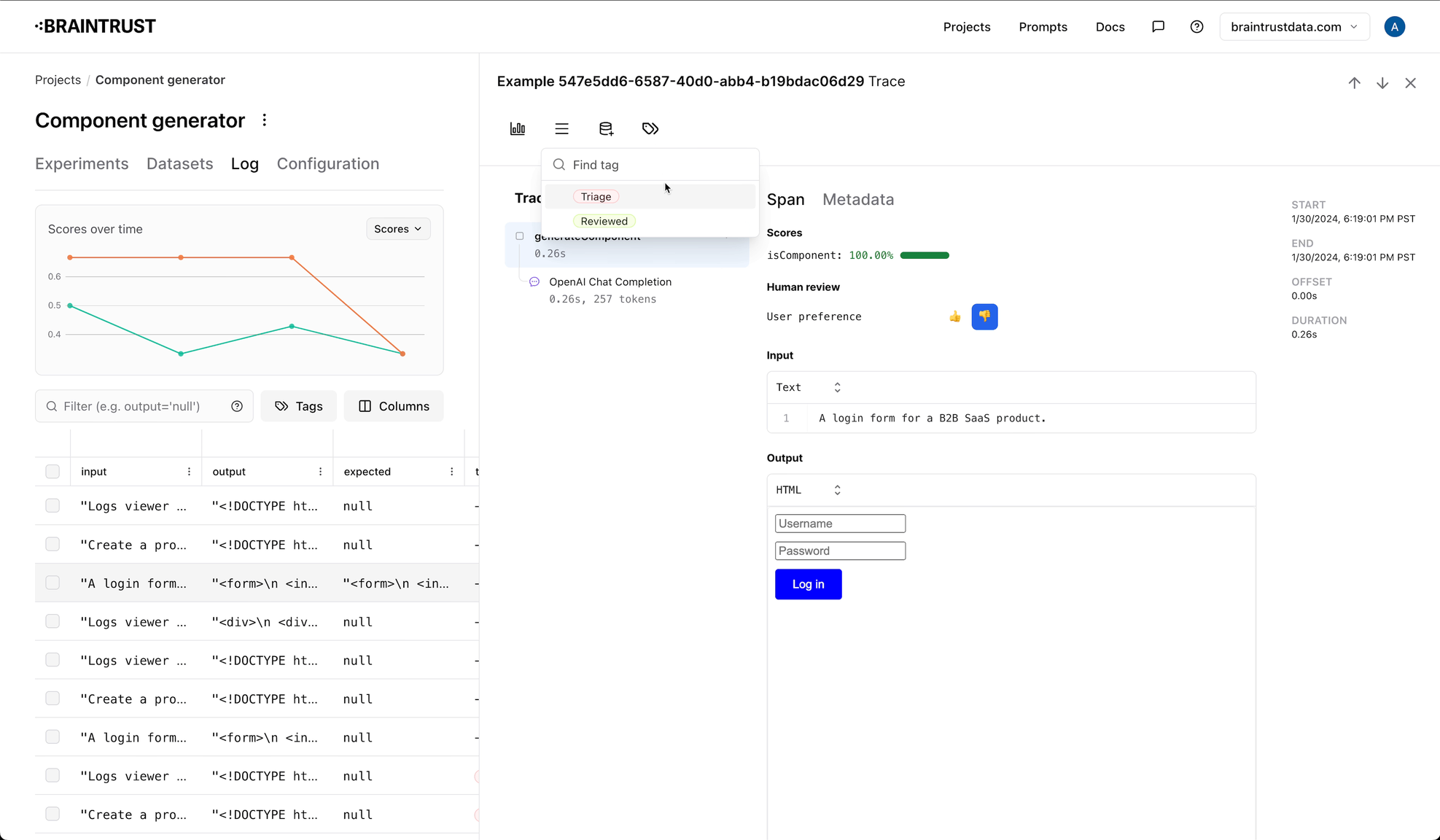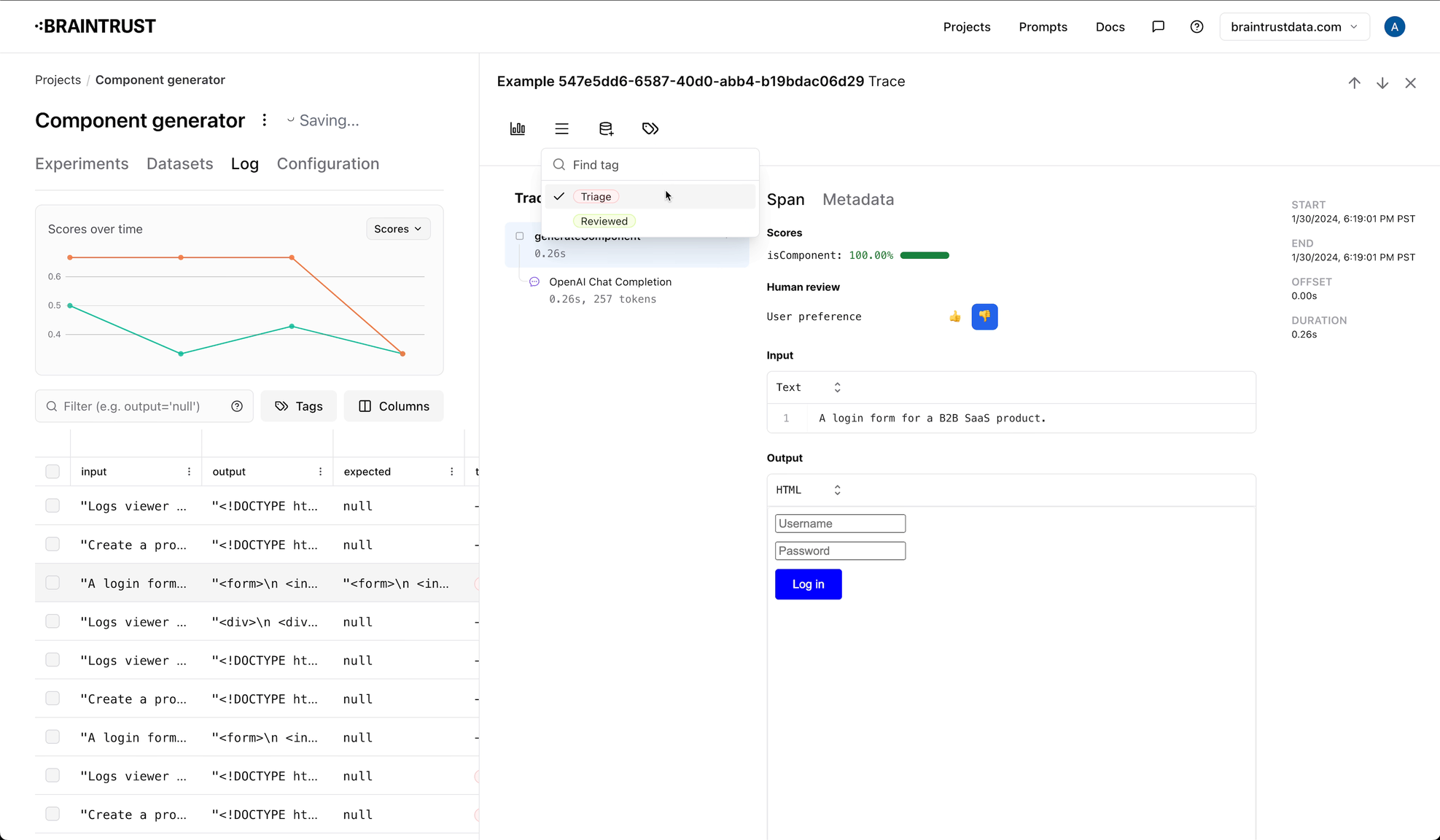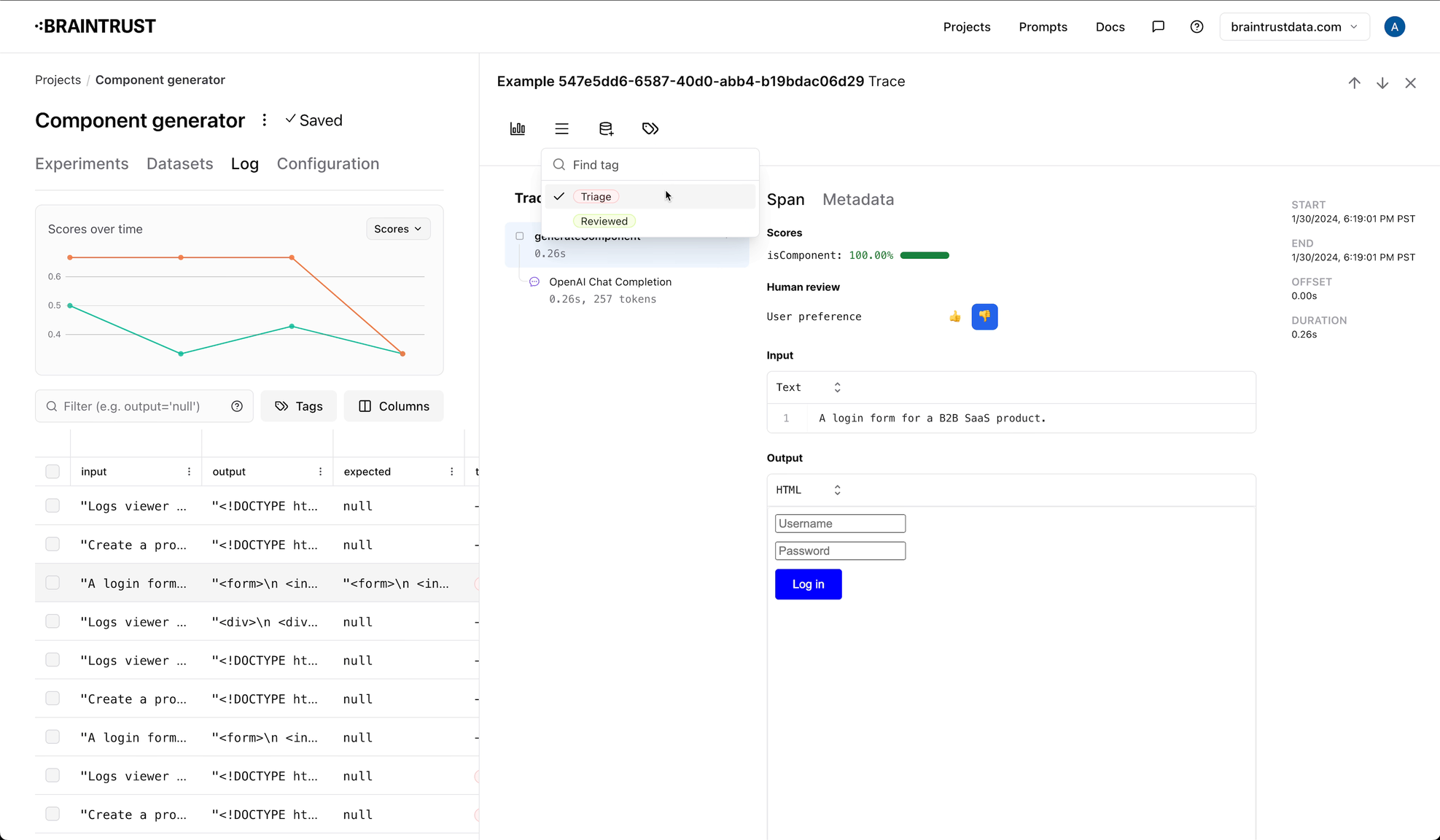
Configuring tags
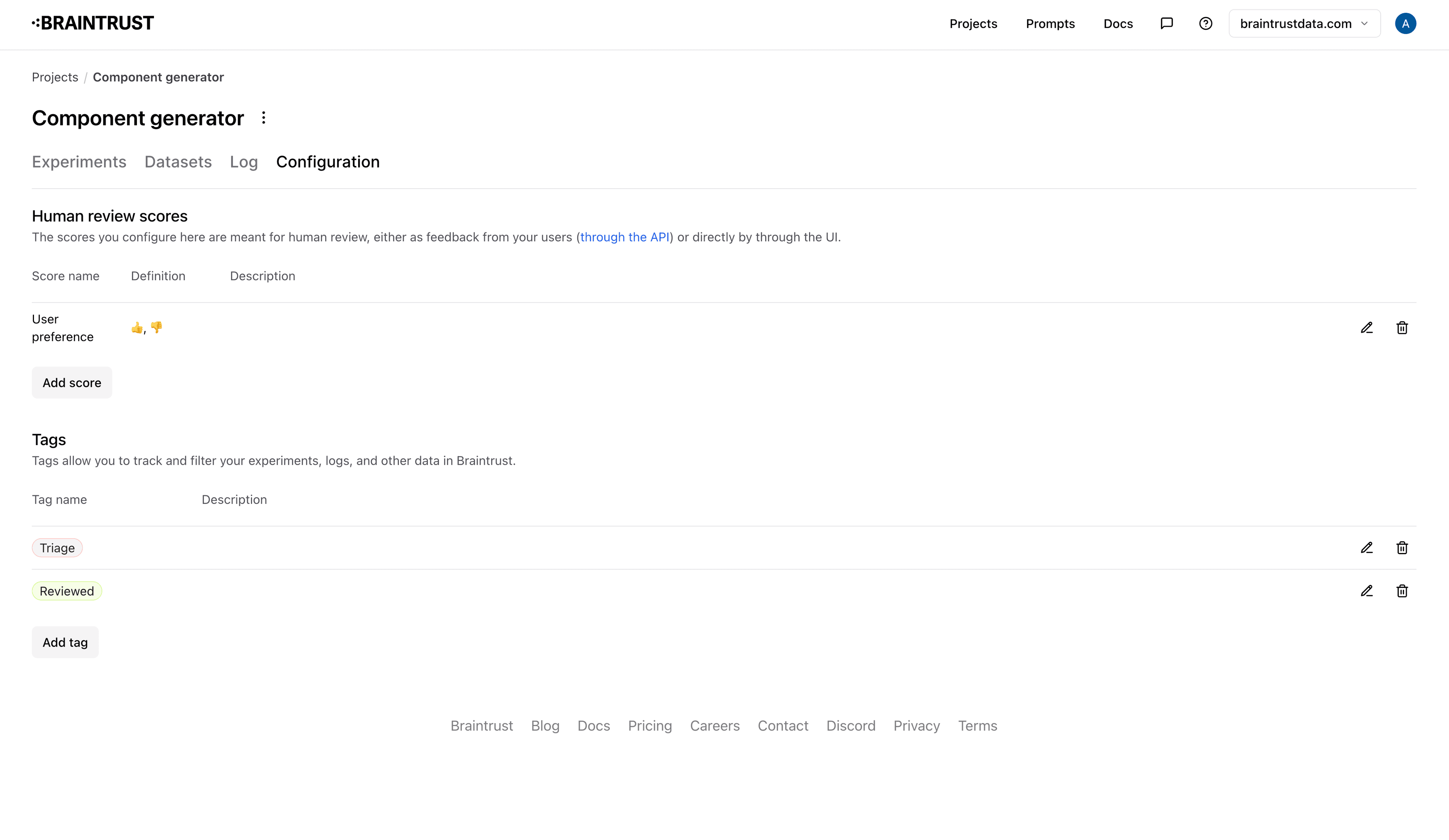
Tags are configured at the project level, and in addition to a name, you can also specify a color and description. To configure tags, navigate to the "Configuration" tab in a project, where you can add, modify, and delete tags.
Adding tags in the SDK
You can also add tags to logs using the SDK. To do so, simply specify the tags field when you log data.
import { initLogger } from "braintrust";
logger = initLogger({
projectName
apiKey: process.env.BRAINTRUST_API_KEY,
});
export async function POST(req: Request) {
return logger.traced(async (span) => {
const { body } = req;
const result = await someLLMFunction(body);
span.log({ input: body, output: result, tags: ["user-action"] });
return {
result,
requestId: span.span_id,
};
});
}Tags can only be applied to top-level spans, e.g those created via traced()
or logger.startSpan()/ logger.start_span(). You cannot apply tags to
subspans (those created from another span), because they are properties of the
whole trace, not individual spans.
You can also apply tags while capturing feedback via the logFeedback() / log_feedback() method.
import { initLogger } from "braintrust";
logger = initLogger({
projectName
apiKey: process.env.BRAINTRUST_API_KEY,
});
export async function POSTFeedback(req: Request) {
logger.logFeedback({
id: span.id, // Use the newly created span's id, instead of the original request's id
comment: req.body.comment,
scores: {
correctness: req.body.score,
},
metadata: {
user_id: req.user.id,
},
tags: ["user-feedback"],
});
}Filtering by tags
To filter by tags, simply select the tags you want to filter by in the UI.

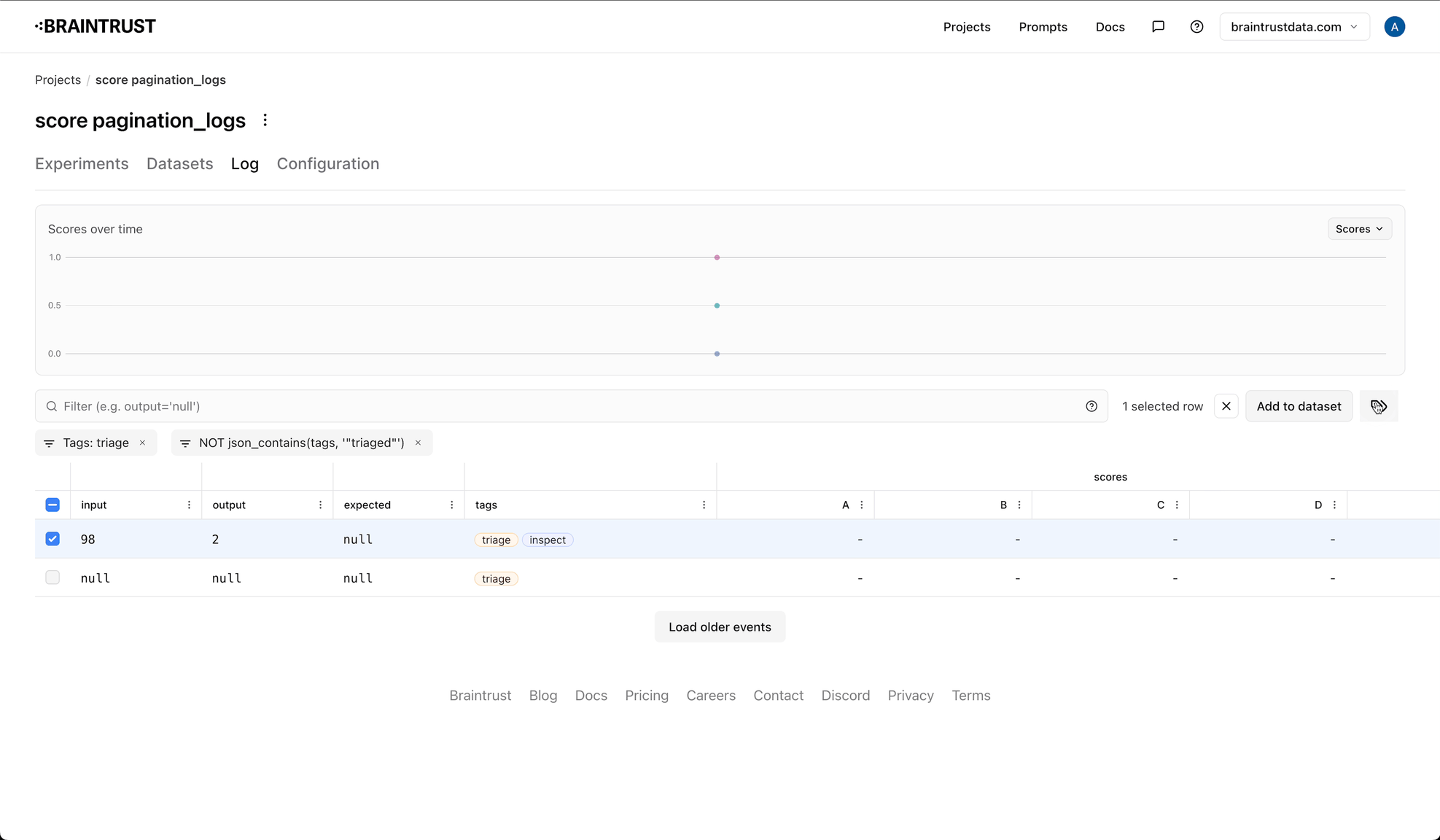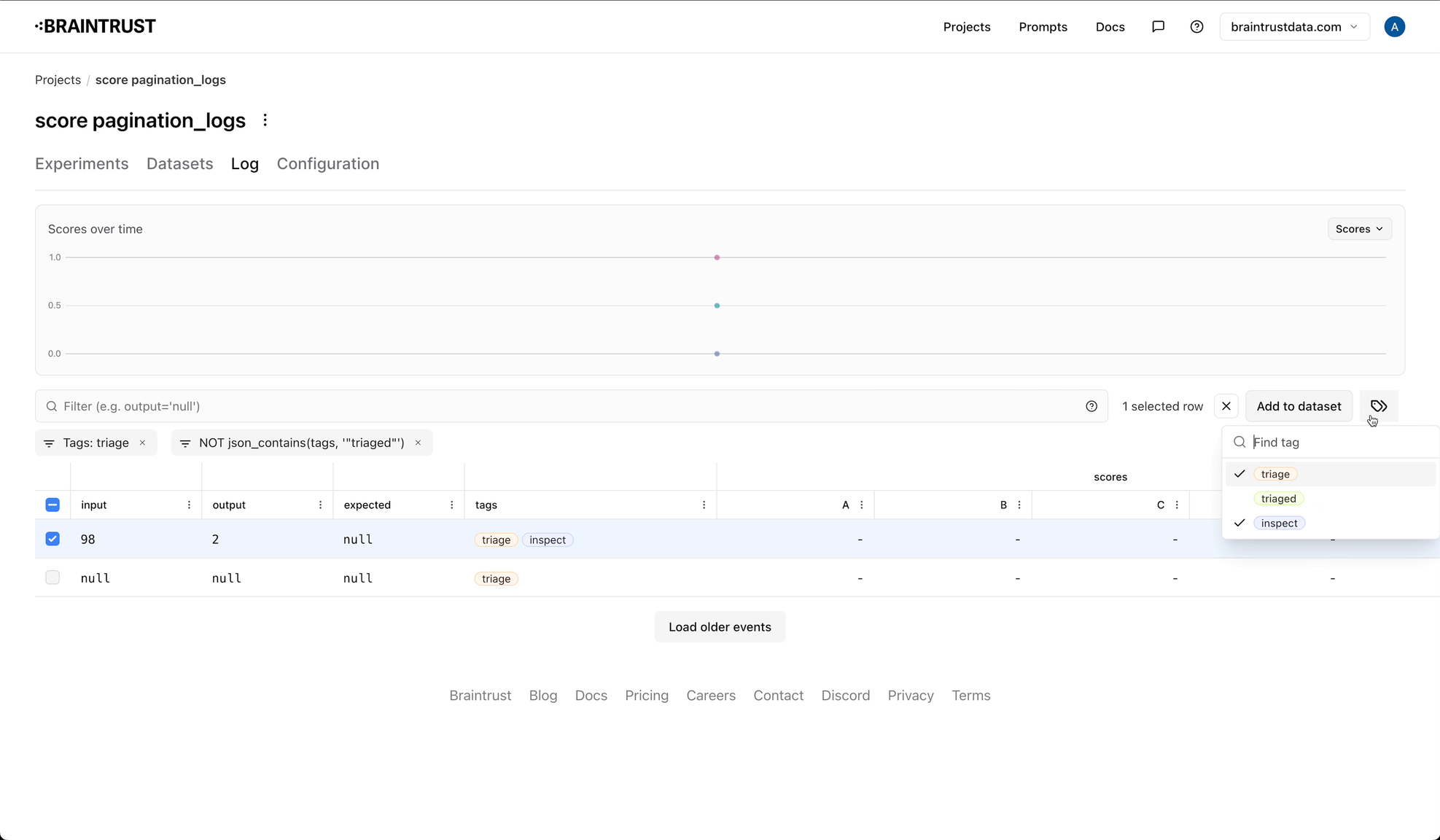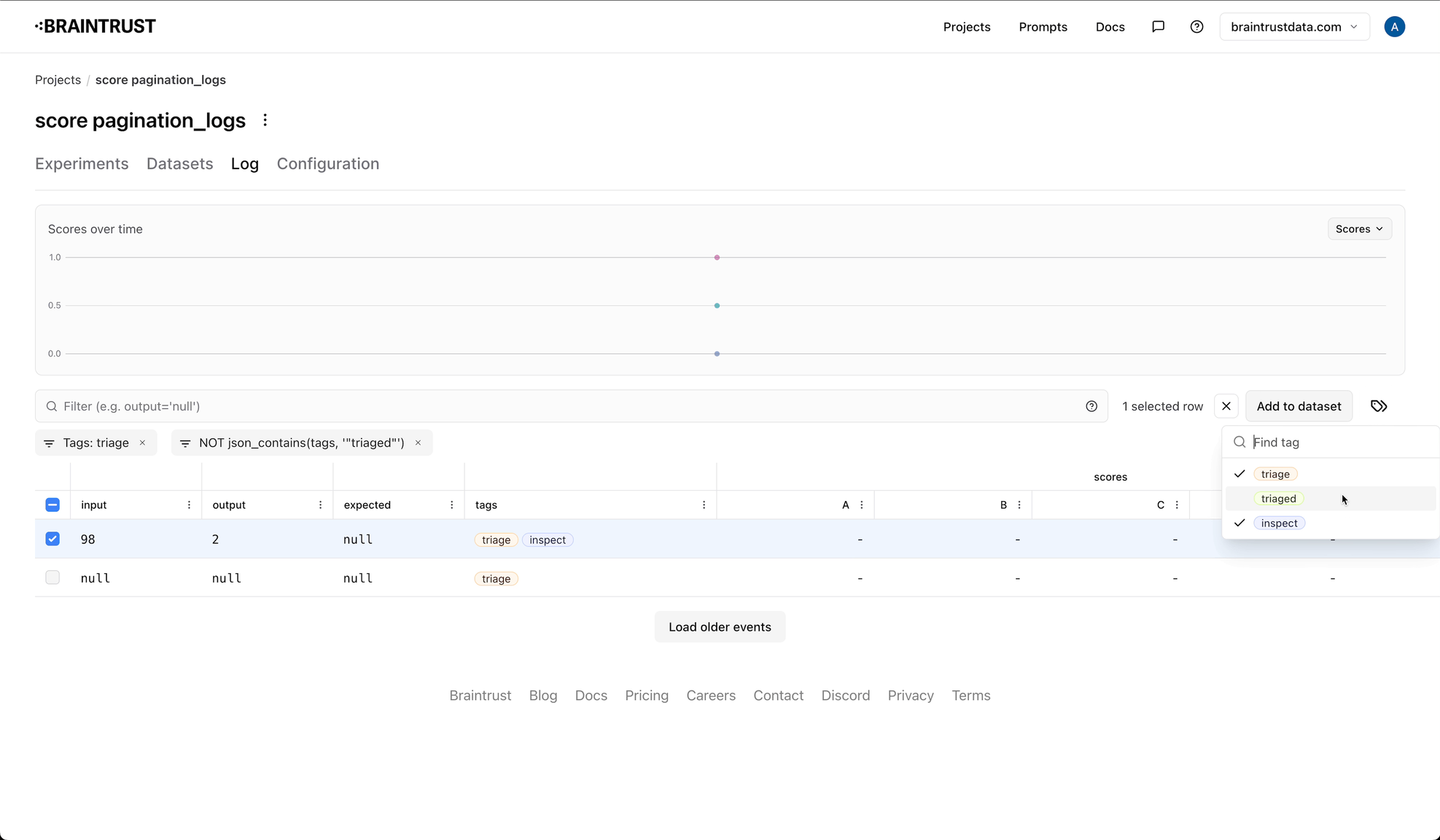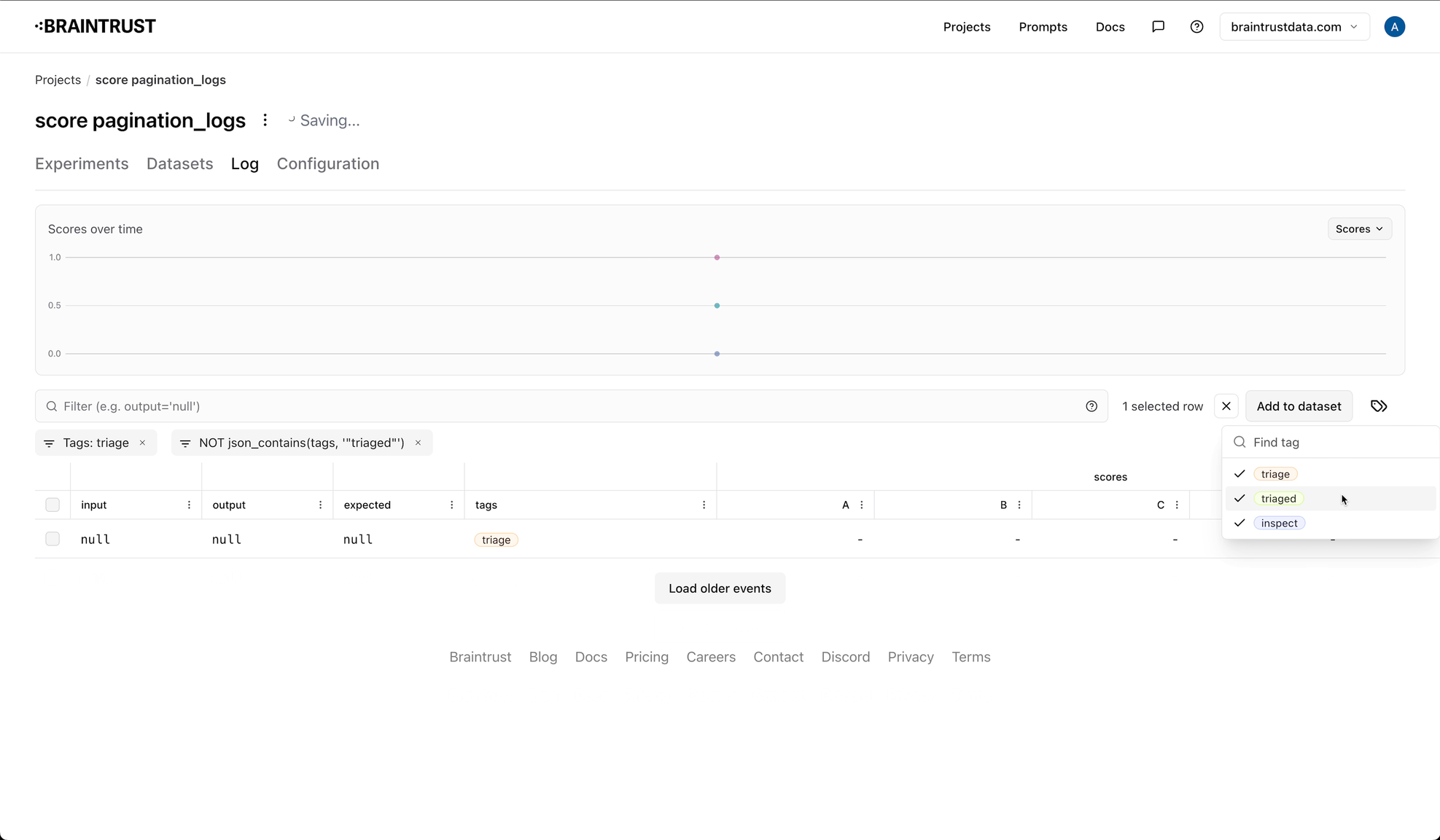
Using tags to create queues
You can also use tags to create queues, which are a way to organize logs into groups. Queues are useful for tracking logs you want to
look at later, or for organizing logs into different categories. To create a queue, you should create two tags: one for the queue,
and one to indicate that the event is no longer in the queue. For example, you might create a triage tag, and a triaged tag.
As you're reviewing logs, simply add the triage tag to the logs you want to review later. To see the logs in the queue, filter by the
triage tag. You can add an additional label, like -tags:triaged to exclude logs that have been marked as done.
-tags:triaged is not formal syntax in Braintrust, but our AI search knows to
look for it, or terms like it, to exclude logs with the triaged tag.
Implementation considerations
Data model
- Each log entry is associated with an organization and a project. If you do not specify a project name or id in
initLogger()/init_logger(), the SDK will create and use a project named "Global". - Although logs are associated with a single project, you can still use them in evaluations or datasets that belong to any project.
- Like evaluation experiments, log entries contain optional
input,output,expected,scores,metadata, andmetricsfields. These fields are optional, but we encourage you to use them to provide context to your logs. - Logs are indexed automatically to enable efficient search. When you load logs, Braintrust automatically returns the most recently
updated log entries first. You can also search by arbitrary subfields, e.g.
metadata.user_id = '1234'. Currently, inequality filters, e.g.scores.accuracy > 0.5do not use an index.
Initializing
The initLogger()/init_logger() method initializes the logger. Unlike the experiment init() method, the logger lazily
initializes itself, so that you can call initLogger()/init_logger() at the top of your file (in module scope). The first
time you log() or start a span, the logger will log into Braintrust and retrieve/initialize project details.
Flushing
The SDK can operate in two modes: either it sends log statements to the server after each request, or it buffers them in
memory and sends them over in batches. Batching reduces the number of network requests and makes the log() command as fast as possible.
Each SDK flushes logs to the server as fast as possible, and attempts to flush any outstanding logs when the program terminates.
You can enable background batching by setting the asyncFlush / async_flush flag to true in initLogger()/init_logger().
When async flush mode is on, you can use the .flush() method to manually flush any outstanding logs to the server.
// In the JS SDK, `asyncFlush` is false by default.
const logger = initLogger({
projectName: "My Project",
apiKey: process.env.BRAINTRUST_API_KEY,
asyncFlush: true,
});
...
// Some function that is called while cleaning up resources
async function cleanup() {
await logger.flush();
}Serverless environments
The asyncFlush / async_flush flag controls whether or not logs are flushed
when a trace completes. This flag should be set to false in serverless environments where the process
may halt as soon as the request completes. By default, asyncFlush is set to false in the Typescript SDK, since
most Typescript applications are serverless, and True in Python.
const logger = initLogger({
projectName: "My Project",
apiKey: process.env.BRAINTRUST_API_KEY,
asyncFlush: false,
});