Classifying news articles

This is a quick tutorial on how to build and evaluate an AI app to classify news titles into categories with BrainTrust.
Before starting, make sure that you have a BrainTrust account. If you do not, please sign up first. After this tutorial, learn more by visiting the docs.
First, we'll install some dependencies.
%pip install -U braintrust openai datasets autoevalsNext, we'll import the ag_news dataset from Huggingface.
from datasets import load_dataset
# Load dataset from Huggingface.
dataset = load_dataset("ag_news", split="train")
# Extract category names from the dataset and build a map from index to
# category name. We will use this to compare the expected categories to
# those produced by the model.
category_names = dataset.features["label"].names
category_map = dict([name for name in enumerate(category_names)])
# Shuffle and trim to 20 datapoints. Restructure our dataset
# slightly so that each item in the list contains an input
# being the title and the expected category index label.
trimmed_dataset = dataset.shuffle(seed=42)[:20]
articles = [
{
"input": trimmed_dataset["text"][i],
"expected": category_map[trimmed_dataset["label"][i]],
}
for i in range(len(trimmed_dataset["text"]))
]Writing the initial prompts
Let's first write a prompt for categorizing a title for just one article. With BrainTrust, you can use any library you'd like — OpenAI, OSS models, LangChain, Guidance, or even just direct calls to an LLM.
The prompt provides the article's title to the model, and asks it to generate a category.
# Here's the input and expected output for the first article in our dataset.
test_article = articles[0]
test_text = test_article["input"]
expected_text = test_article["expected"]
print("Article Title:", test_text)
print("Article Label:", expected_text)Next, let's initialize an OpenAI client with your API key. We'll use wrap_openai from the braintrust library to automatically instrument the client to track useful metrics for you. When Braintrust is not initialized, wrap_openai is a no-op.
import braintrust
import os
from openai import OpenAI
client = braintrust.wrap_openai(
OpenAI(api_key=os.environ.get("OPENAI_API_KEY", "Your OPENAI_API_KEY here"))
)It's time to try writing a prompt and classifying a title! We'll define a classify_article function that takes an input title and returns a category. The @braintrust.traced decorator, like wrap_openai above, will help us trace inputs, outputs, and timing and is a no-op when Braintrust is not active.
MODEL = "gpt-3.5-turbo"
SEED = 123
@braintrust.traced
def classify_article(input):
messages = [
{
"role": "system",
"content": """You are an editor in a newspaper who helps writers identify the right category for their news articles,
by reading the article's title. The category should be one of the following: World, Sports, Business or Sci-Tech. Reply with one word corresponding to the category.""",
},
{
"role": "user",
"content": "Article title: {article_title} Category:".format(article_title=input),
},
]
result = client.chat.completions.create(
model=MODEL,
messages=messages,
max_tokens=10,
seed=SEED,
)
category = result.choices[0].message.content
return category
test_classify = classify_article(test_text)
print("Input:", test_text)
print("Classified as:", test_classify)
print("Score:", 1 if test_classify == expected_text else 0)Running across the dataset
Now that we have automated classifying titles, we can test the full set of articles using Braintrust's Eval function. Behind the scenes, Eval will in parallel run the classify_article function on each article in the dataset, and then compare the results to the ground truth labels using a simple Levenshtein scorer. When it finishes running, it will print out the results with a link to Braintrust to dig deeper.
from autoevals import Levenshtein
braintrust.login(api_key=os.environ.get("BRAINTRUST_API_KEY", "Your BRAINTRUST_API_KEY here"))
await braintrust.Eval(
"Classifying News Articles Cookbook",
data=articles,
task=classify_article,
scores=[Levenshtein],
)Pause and analyze the results in BrainTrust!
The cell above will print a link to the BrainTrust experiment. Click on it to investigate where we can improve our AI app.
Looking at our results table (in the screenshot below), we incorrectly output Sci-Tech instead of Sci/Tech which results in a failed eval test case. Let's fix it.
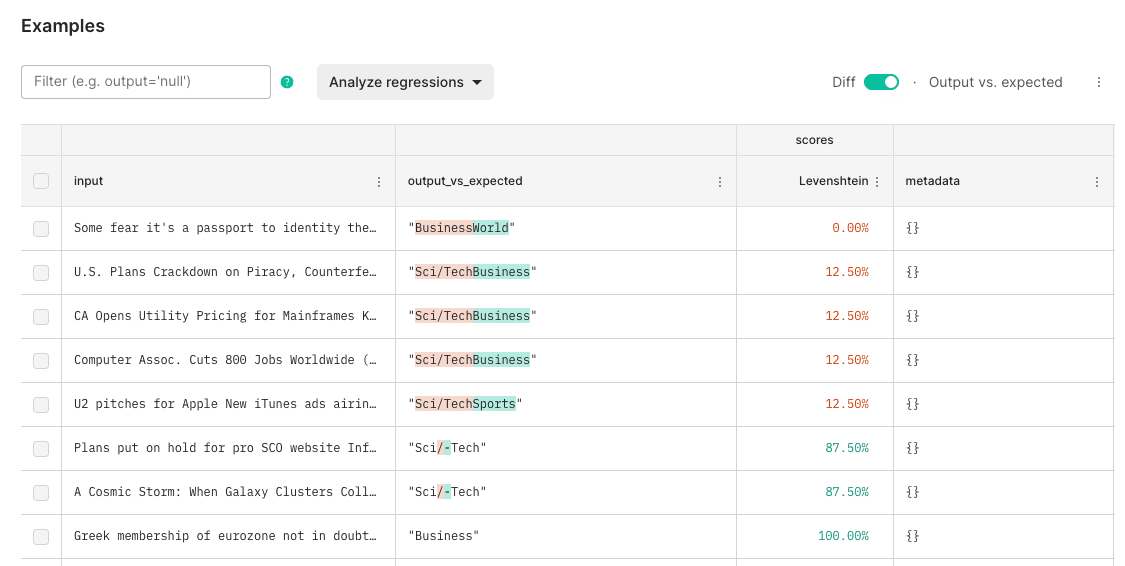
Reproducing an example
First, let's see if we can reproduce this issue locally. We can test an article corresponding to the Sci/Tech category and reproduce the evaluation:
sci_tech_article = [a for a in articles if "Galaxy Clusters" in a["input"]][0]
print(sci_tech_article["input"])
print(sci_tech_article["expected"])
out = classify_article(sci_tech_article["expected"])
print(out)Fixing the prompt
Have you spotted the issue? It looks like we misspelled one of the categories in our prompt. The dataset's categories are World, Sports, Business and Sci/Tech - but we are using Sci-Tech in our prompt. Let's fix it:
@braintrust.traced
def classify_article(input):
messages = [
{
"role": "system",
"content": """You are an editor in a newspaper who helps writers identify the right category for their news articles,
by reading the article's title. The category should be one of the following: World, Sports, Business or Sci/Tech. Reply with one word corresponding to the category.""",
},
{
"role": "user",
"content": "Article title: {input} Category:".format(input=input),
},
]
result = client.chat.completions.create(
model=MODEL,
messages=messages,
max_tokens=10,
seed=SEED,
)
category = result.choices[0].message.content
return category
result = classify_article(sci_tech_article["input"])
print(result)Evaluate the new prompt
The model classified the correct category Sci/Tech for this example. But, how do we know it works for the rest of the dataset? Let's run a new experiment to evaluate our new prompt using BrainTrust.
await braintrust.Eval(
"Classifying News Articles Cookbook",
data=articles,
task=classify_article,
scores=[Levenshtein],
)Conclusion
Click into the new experiment, and check it out! You should notice a few things:
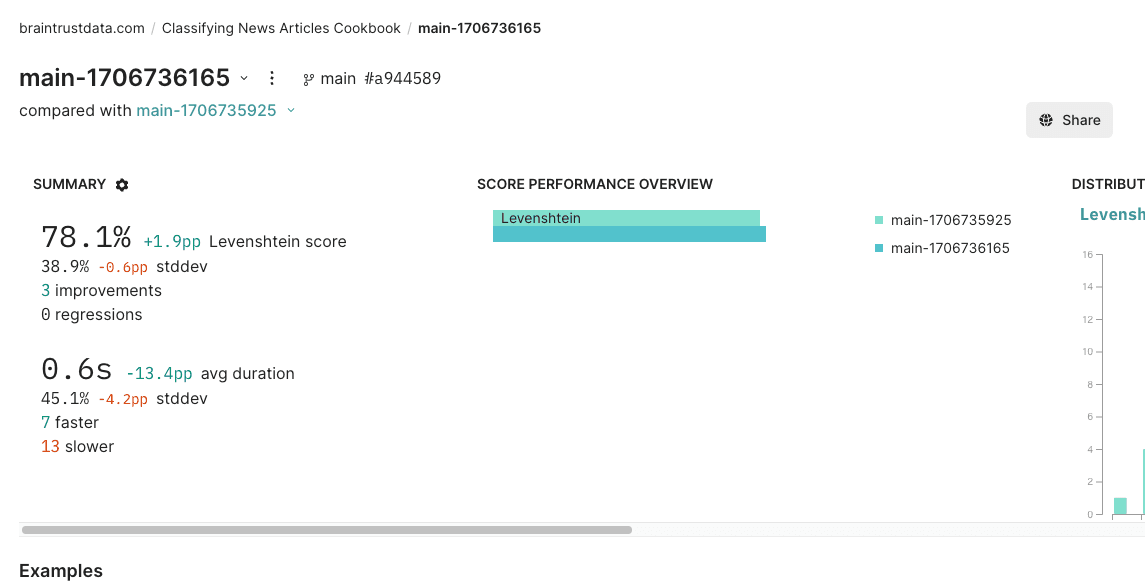
- BrainTrust will automatically compare the new experiment to your previous one.
- You should see the eval scores increase and you can see which test cases improved.
- You can also filter the test cases that have a low score and work on improving the prompt for those.
Now, you are on your journey of building reliable AI apps with BrainTrust!