Coda's Help Desk with and without RAG


Welcome to BrainTrust! In this notebook, you'll build and evaluate an AI app that answers questions about Coda's help desk.
To provide the LLM with relevant information from Coda's help desk, we'll use a technique called RAG (retrieval-augmented generation) to infuse our prompts with text from the most-relevant sections of their docs. To evaluate the performance of our app, we'll use an LLM to generate question-answer pairs from the docs, and we'll use a technique called model graded evaluation to automatically evaluate the final responses against the expected answers.
Before starting, please make sure that you have a BrainTrust account. If you do not, please sign up or get in touch. After this tutorial, feel free to dig deeper by visiting the docs.
%pip install -U autoevals braintrust requests openai lancedb markdownifyQA_GEN_MODEL = "gpt-3.5-turbo"
QA_ANSWER_MODEL = "gpt-3.5-turbo"
QA_GRADING_MODEL = "gpt-4"
RELEVANCE_MODEL = "gpt-3.5-turbo"
NUM_SECTIONS = 20
NUM_QA_PAIRS = 20 # Increase this number to test at a larger scaleDownload Markdown docs from Coda's help desk
Let's start by downloading the Coda docs and splitting them into their constituent Markdown sections.
import asyncio
import os
import re
import time
import autoevals
import braintrust
import markdownify
import openai
import requests
data = requests.get(
"https://gist.githubusercontent.com/wong-codaio/b8ea0e087f800971ca5ec9eef617273e/raw/39f8bd2ebdecee485021e20f2c1d40fd649a4c77/articles.json"
).json()
markdown_docs = [{"id": row["id"], "markdown": markdownify.markdownify(row["body"])} for row in data]
i = 0
markdown_sections = []
for markdown_doc in markdown_docs:
sections = re.split(r"(.*\n=+\n)", markdown_doc["markdown"])
current_section = ""
for section in sections:
if not section.strip():
continue
if re.match(r".*\n=+\n", section):
current_section = section
else:
section = current_section + section
markdown_sections.append({"doc_id": markdown_doc["id"], "section_id": i, "markdown": section.strip()})
current_section = ""
i += 1
print(f"Downloaded {len(markdown_sections)} Markdown sections. Here are the first 3:")
markdown_sections[:3]Use the Braintrust AI proxy to access the OpenAI API
The Braintrust AI proxy provides a single API to access OpenAI and Anthropic models, LLaMa 2, Mistral and others. Here we use it to access gpt-3.5-turbo. Because the Braintrust AI proxy automatically caches and reuses results (when temperature=0 or the seed parameter is set, or when the caching mode is set to always), we can re-evaluate the following prompts many times without incurring additional API costs.
If you'd prefer not to use the proxy, simply omit the base_url and default_headers parameters below.
client = braintrust.wrap_openai(openai.AsyncOpenAI(
base_url="https://braintrustproxy.com/v1",
default_headers={"x-bt-use-cache": "always"},
api_key=os.environ.get("OPENAI_API_KEY", "Your OPENAI_API_KEY here"),
))Generate question-answer pairs
Before we start evaluating some prompts, let's first use the LLM to generate a bunch of question/answer pairs from the text at hand. We'll use these QA pairs as ground truth when grading our models later.
import json
from typing import List
from pydantic import BaseModel, Field
class QAPair(BaseModel):
questions: List[str] = Field(
..., description="List of questions, all with the same meaning but worded differently"
)
answer: str = Field(..., description="Answer")
class QAPairs(BaseModel):
pairs: List[QAPair] = Field(..., description="List of question/answer pairs")
async def produce_candidate_questions(row):
response = await client.chat.completions.create(
model=QA_GEN_MODEL,
messages=[{"role": "user", "content": f"""\
Please generate 8 question/answer pairs from the following text. For each question, suggest
2 different ways of phrasing the question, and provide a unique answer.
Content:
{row['markdown']}
""",
}],
functions=[
{
"name": "propose_qa_pairs",
"description": "Propose some question/answer pairs for a given document",
"parameters": QAPairs.schema(),
}
],
)
pairs = QAPairs(**json.loads(response.choices[0].message.function_call.arguments))
return pairs.pairsall_candidates_tasks = [
asyncio.create_task(produce_candidate_questions(a)) for a in markdown_sections[:NUM_SECTIONS]
]
all_candidates = [await f for f in all_candidates_tasks]
data = []
row_id = 0
for row, doc_qa in zip(markdown_sections[:NUM_SECTIONS], all_candidates):
for i, qa in enumerate(doc_qa):
for j, q in enumerate(qa.questions):
data.append(
{
"input": q,
"expected": qa.answer,
"metadata": {
"document_id": row["doc_id"],
"section_id": row["section_id"],
"question_idx": i,
"answer_idx": j,
"id": row_id,
"split": "test" if j == len(qa.questions) - 1 and j > 0 else "train",
},
}
)
row_id += 1
print(f"Generated {len(data)} QA pairs. Here are the first 10...")
for x in data[:10]:
print(x)Evaluate a context-free prompt (no RAG)
Now let's evaluate a simple prompt that poses each question without providing any context from the Markdown docs. We'll evaluate this naive approach using (again) gpt-3.5-turbo, with the Factuality prompt from the Braintrust AutoEvals library.
async def simple_qa(input):
completion = await client.chat.completions.create(
model=QA_ANSWER_MODEL,
messages=[{"role": "user", "content": f"""\
Please answer the following question:
Question: {input}
""",
}],
)
return completion.choices[0].message.content
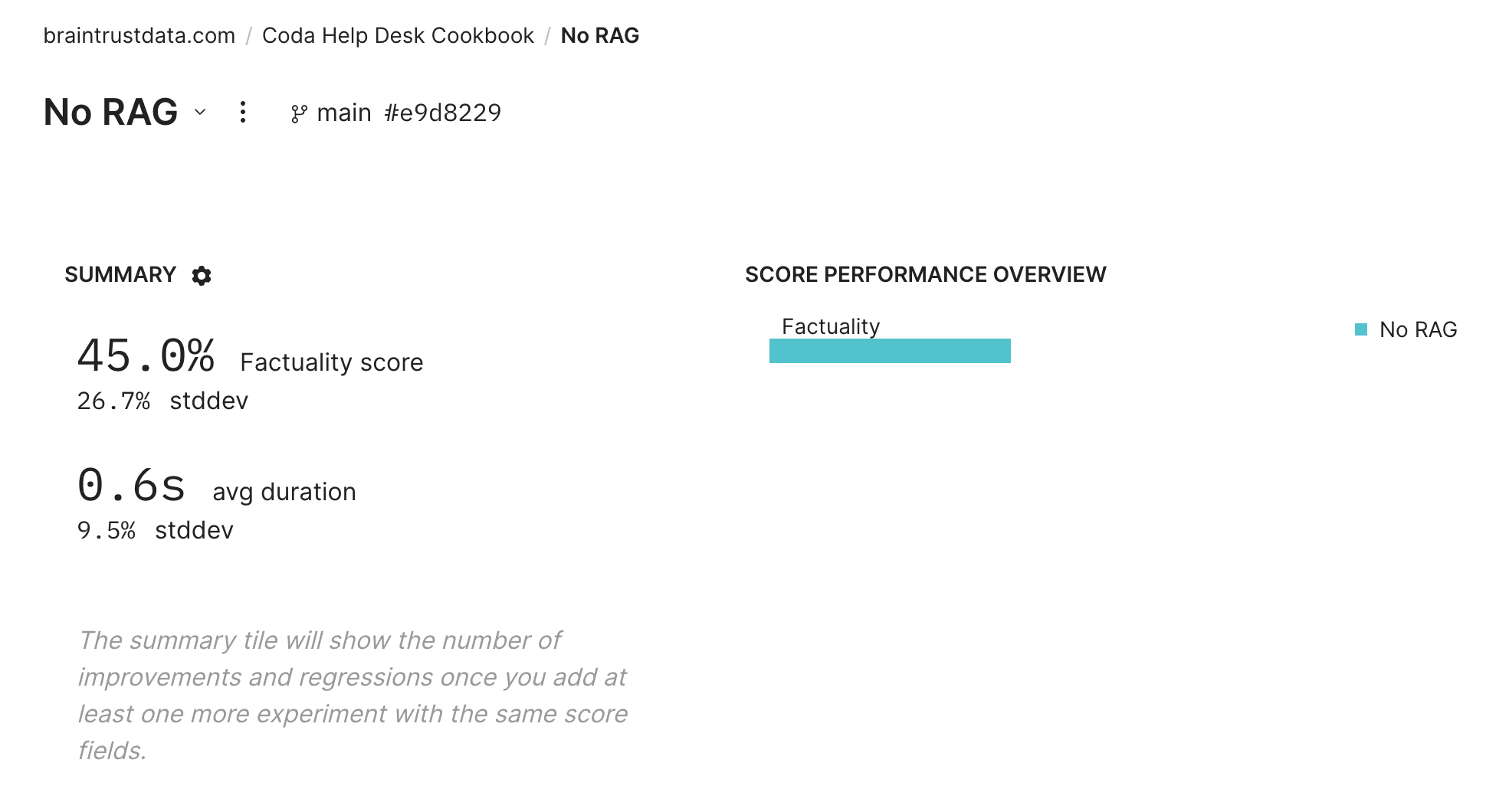
await braintrust.Eval(
name="Coda Help Desk Cookbook",
experiment_name="No RAG",
data=data[:NUM_QA_PAIRS],
task=simple_qa,
scores=[autoevals.Factuality(model=QA_GRADING_MODEL)],
)Pause and click into the experiment in Braintrust!
The cell above will print a link to a BrainTrust experiment -- click on it to view our baseline eval.
Try using RAG to improve performance
Let's see if RAG (retrieval-augmented generation) can improve our results on this task.
First we'll compute embeddings for each Markdown section using text-embedding-ada-002 and create an index over the embeddings in LanceDB, a vector database. Then, for any given query, we can convert it to an embedding and efficiently find the most relevant context for an input query by converting it into an embedding and finding the best matches embedding space, and provide the corresponding text as additional context in our prompt.
import tempfile
import lancedb
tempdir = tempfile.TemporaryDirectory()
LANCE_DB_PATH = os.path.join(tempdir.name, "docs-lancedb")
@braintrust.traced
async def embed_text(text):
params = dict(input=text, model="text-embedding-ada-002")
response = await client.embeddings.create(**params)
embedding = response.data[0].embedding
braintrust.current_span().log(
metrics={"tokens": response.usage.total_tokens, "prompt_tokens": response.usage.prompt_tokens},
metadata={"model": response.model},
input=text,
output=embedding,
)
return embedding
embedding_tasks = [asyncio.create_task(embed_text(row["markdown"])) for row in markdown_sections[:NUM_SECTIONS]]
embeddings = [await f for f in embedding_tasks]
db = lancedb.connect(LANCE_DB_PATH)
try:
db.drop_table("sections")
except:
pass
table = db.create_table(
"sections",
data=[
{"doc_id": row["doc_id"], "section_id": row["section_id"], "vector": embedding}
for (row, embedding) in zip(markdown_sections[:NUM_SECTIONS], embeddings)
],
)Use AI to judge relevance of retrieved documents
We're almost there! One more trick -- let's actually retrieve a few more of the best-matching candidates from the vector database than we intend to use, then use gpt-3.5-turbo to score the relevance of each candidate to the input query. We'll use the TOP_K blurbs by relevance score in our QA prompt -- this should be a little more intelligent than just using the closest embeddings.
TOP_K = 2
@braintrust.traced
async def relevance_score(query, document):
response = await client.chat.completions.create(
model=RELEVANCE_MODEL,
messages=[{"role": "user", "content": f"""\
Consider the following query and a document
Query:
{query}
Document:
{document}
Please score the relevance of the document to a query, on a scale of 0 to 1.
""",
}],
functions=[
{
"name": "has_relevance",
"description": "Declare the relevance of a document to a query",
"parameters": {
"type": "object",
"properties": {
"score": {"type": "number"},
},
},
}
],
)
arguments = response.choices[0].message.function_call.arguments
result = json.loads(arguments)
braintrust.current_span().log(
input={"query": query, "document": document},
output=result,
)
return result["score"]
async def retrieval_qa(input):
embedding = await embed_text(input)
with braintrust.current_span().start_span(name="vector search", input=input) as span:
result = table.search(embedding).limit(TOP_K + 3).to_arrow().to_pylist()
docs = [markdown_sections[i["section_id"]]["markdown"] for i in result]
relevance_scores = []
for doc in docs:
relevance_scores.append(await relevance_score(input, doc))
span.log(
output=[
{"doc": markdown_sections[r["section_id"]]["markdown"], "distance": r["_distance"]} for r in result
],
metadata={"top_k": TOP_K, "retrieval": result},
scores={
"avg_relevance": sum(relevance_scores) / len(relevance_scores),
"min_relevance": min(relevance_scores),
"max_relevance": max(relevance_scores),
},
)
context = "\n------\n".join(docs[:TOP_K])
completion = await client.chat.completions.create(
model=QA_ANSWER_MODEL,
messages=[{"role": "user", "content": f"""\
Given the following context
{context}
Please answer the following question:
Question: {input}
""",
}],
)
return completion.choices[0].message.contentRun the RAG evaluation
await braintrust.Eval(
name="Coda Help Desk Cookbook",
experiment_name=f"RAG TopK={TOP_K}",
data=data[:NUM_QA_PAIRS],
task=retrieval_qa,
scores=[autoevals.Factuality(model=QA_GRADING_MODEL)],
)
Summary
Click into the new experiment and check it out. You should notice a few things:
- Braintrust will automatically compare the new experiment to your previous one.
- You should see an increase in scores with RAG. Click around to see exactly which examples improved.
- Try playing around with the constants set at the beginning of this tutorial, such as
NUM_QA_PAIRS, to evaluate on a larger dataset.
We hope you had fun with this tutorial! You can learn more about Braintrust at https://www.braintrustdata.com/docs.