Improving Github issue titles using their contents

This tutorial will teach you how to use Braintrust to generate better titles for Github issues, based on their content. This is a great way to learn how to work with text and evaluate subjective criteria, like summarization quality.
We'll use a technique called model graded evaluation to automatically evaluate the newly generated titles against the original titles, and improve our prompt based on what we find.
Before starting, please make sure that you have a Braintrust account. If you do not, please sign up. After this tutorial, feel free to dig deeper by visiting the docs.
Installing dependencies
To see a list of dependencies, you can view the accompanying package.json file. Feel free to copy/paste snippets of this code to run in your environment, or use tslab to run the tutorial in a Jupyter notebook.
Downloading the data
We'll start by downloading some issues from Github using the octokit SDK. We'll use the popular open source project next.js.
import { Octokit } from "@octokit/core";
const ISSUES = [
"https://github.com/vercel/next.js/issues/59999",
"https://github.com/vercel/next.js/issues/59997",
"https://github.com/vercel/next.js/issues/59995",
"https://github.com/vercel/next.js/issues/59988",
"https://github.com/vercel/next.js/issues/59986",
"https://github.com/vercel/next.js/issues/59971",
"https://github.com/vercel/next.js/issues/59958",
"https://github.com/vercel/next.js/issues/59957",
"https://github.com/vercel/next.js/issues/59950",
"https://github.com/vercel/next.js/issues/59940",
];
// Octokit.js
// https://github.com/octokit/core.js#readme
const octokit = new Octokit({
auth: process.env.GITHUB_ACCESS_TOKEN || "Your Github Access Token",
});
async function fetchIssue(url: string) {
// parse url of the form https://github.com/supabase/supabase/issues/15534
const [owner, repo, _, issue_number] = url!.trim().split("/").slice(-4);
const data = await octokit.request(
"GET /repos/{owner}/{repo}/issues/{issue_number}",
{
owner,
repo,
issue_number: parseInt(issue_number),
headers: {
"X-GitHub-Api-Version": "2022-11-28",
},
}
);
return data.data;
}
const ISSUE_DATA = await Promise.all(ISSUES.map(fetchIssue));Let's take a look at one of the issues:
console.log(ISSUE_DATA[0].title);
console.log("-".repeat(ISSUE_DATA[0].title.length));
console.log(ISSUE_DATA[0].body.substring(0, 512) + "...");Generating better titles
Let's try to generate better titles using a simple prompt. We'll use OpenAI, although you could try this out with any model that supports text generation.
We'll start by initializing an OpenAI client and wrapping it with some Braintrust instrumentation. wrapOpenAI
is initially a no-op, but later on when we use Braintrust, it will help us capture helpful debugging information about the model's performance.
import { wrapOpenAI } from "braintrust";
import { OpenAI } from "openai";
const client = wrapOpenAI(
new OpenAI({
apiKey: process.env.OPENAI_API_KEY || "Your OpenAI API Key",
})
);import { ChatCompletionMessageParam } from "openai/resources";
function titleGeneratorMessages(content: string): ChatCompletionMessageParam[] {
return [
{
role: "system",
content:
"Generate a new title based on the github issue. Return just the title.",
},
{
role: "user",
content: "Github issue: " + content,
},
];
}
async function generateTitle(input: string) {
const messages = titleGeneratorMessages(input);
const response = await client.chat.completions.create({
model: "gpt-3.5-turbo",
messages,
seed: 123,
});
return response.choices[0].message.content || "";
}
const generatedTitle = await generateTitle(ISSUE_DATA[0].body);
console.log("Original title: ", ISSUE_DATA[0].title);
console.log("Generated title:", generatedTitle);Scoring
Ok cool! The new title looks pretty good. But how do we consistently and automatically evaluate whether the new titles are better than the old ones?
With subjective problems, like summarization, one great technique is to use an LLM to grade the outputs. This is known as model graded evaluation. Below, we'll use a summarization prompt from Braintrust's open source autoevals library. We encourage you to use these prompts, but also to copy/paste them, modify them, and create your own!
The prompt uses Chain of Thought which dramatically improves a model's performance on grading tasks. Later, we'll see how it helps us debug the model's outputs.
Let's try running it on our new title and see how it performs.
import { Summary } from "autoevals";
await Summary({
output: generatedTitle,
expected: ISSUE_DATA[0].title,
input: ISSUE_DATA[0].body,
// In practice we've found gpt-4 class models work best for subjective tasks, because
// they are great at following criteria laid out in the grading prompts.
model: "gpt-4-1106-preview",
});Initial evaluation
Now that we have a way to score new titles, let's run an eval and see how our prompt performs across all 10 issues.
import { Eval, login } from "braintrust";
login({ apiKey: process.env.BRAINTUST_API_KEY || "Your Braintrust API Key" });
await Eval("Github Issues Cookbook", {
data: () =>
ISSUE_DATA.map((issue) => ({
input: issue.body,
expected: issue.title,
metadata: issue,
})),
task: generateTitle,
scores: [
async ({ input, output, expected }) =>
Summary({
input,
output,
expected,
model: "gpt-4-1106-preview",
}),
],
});
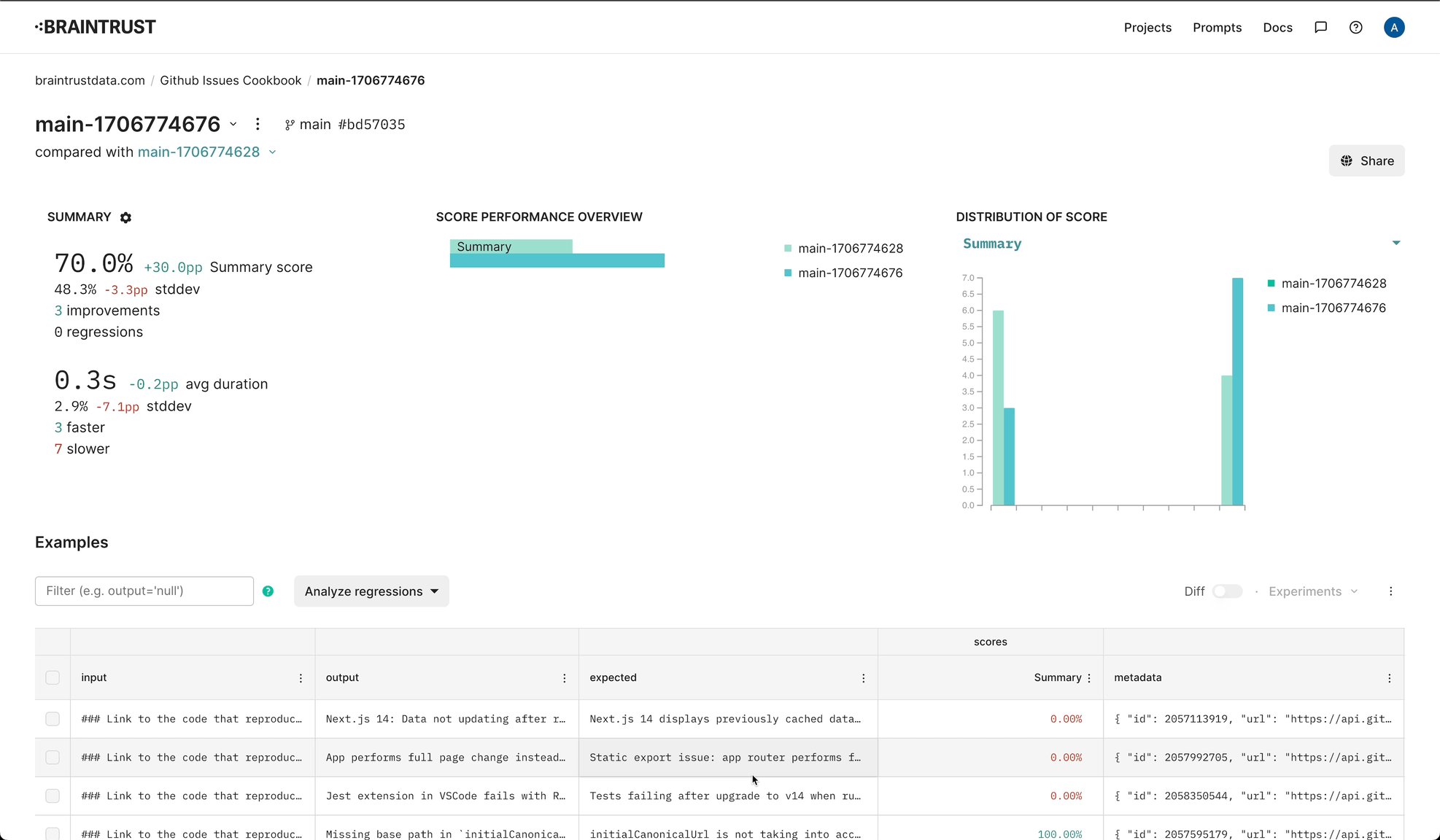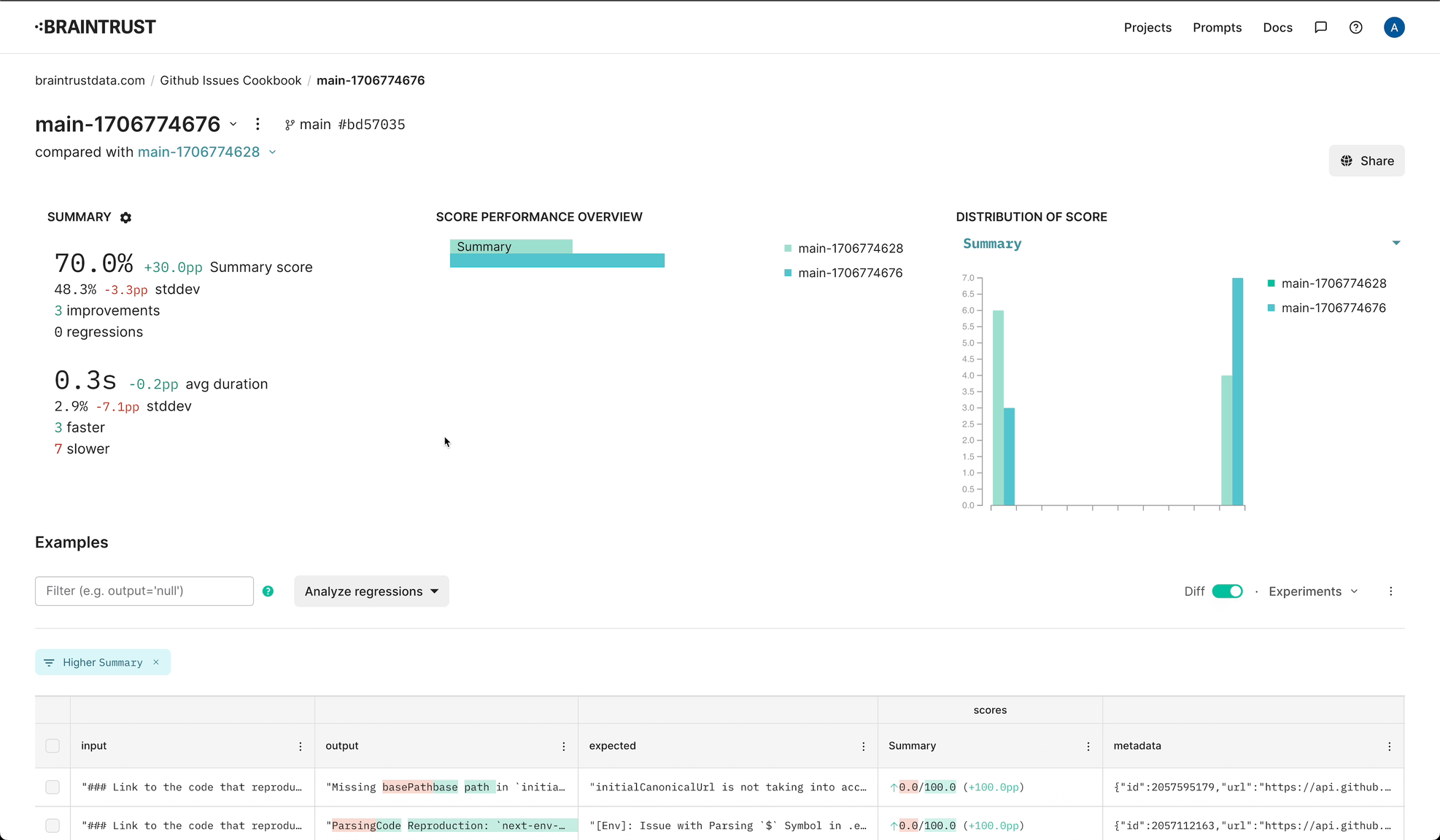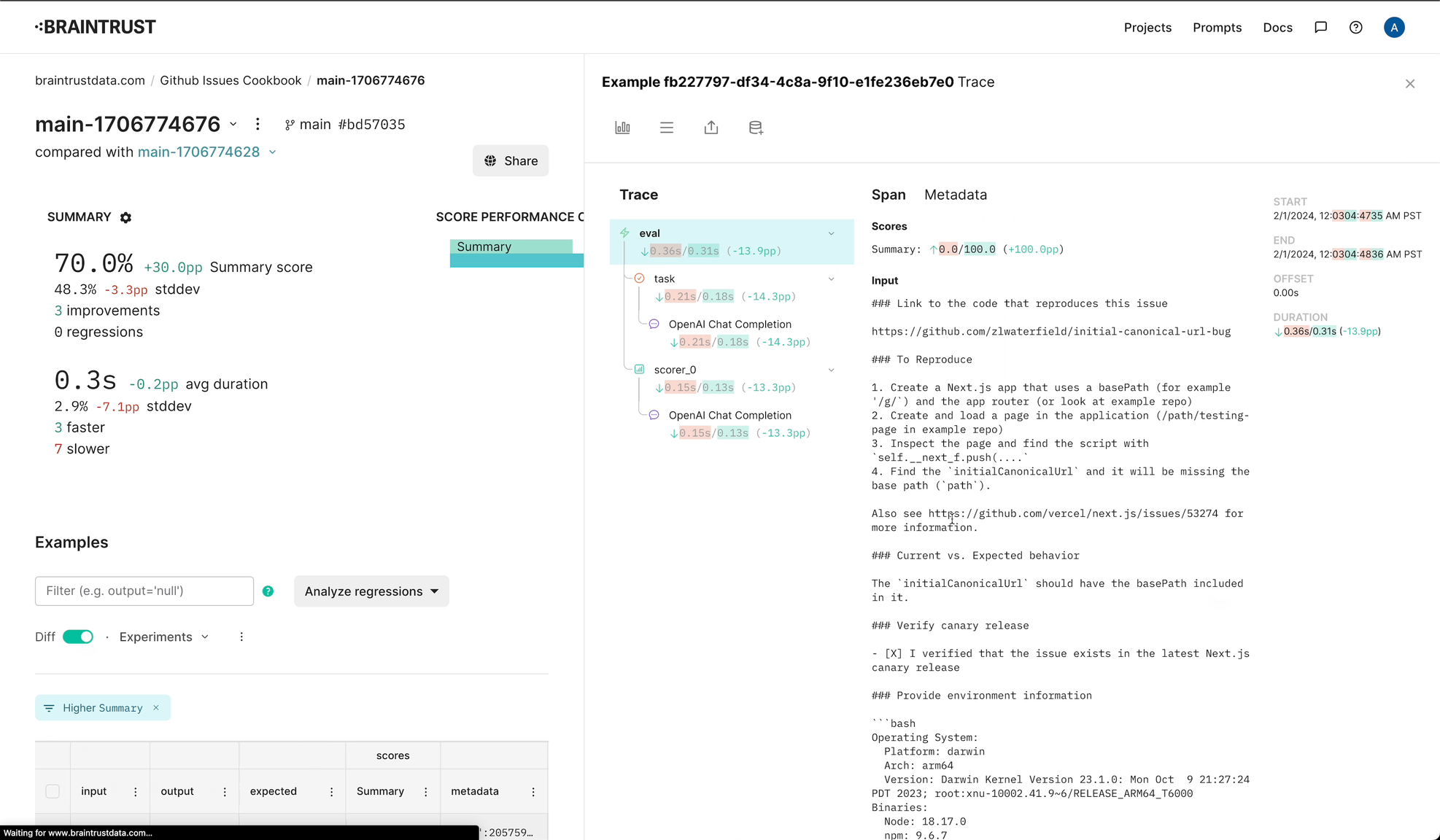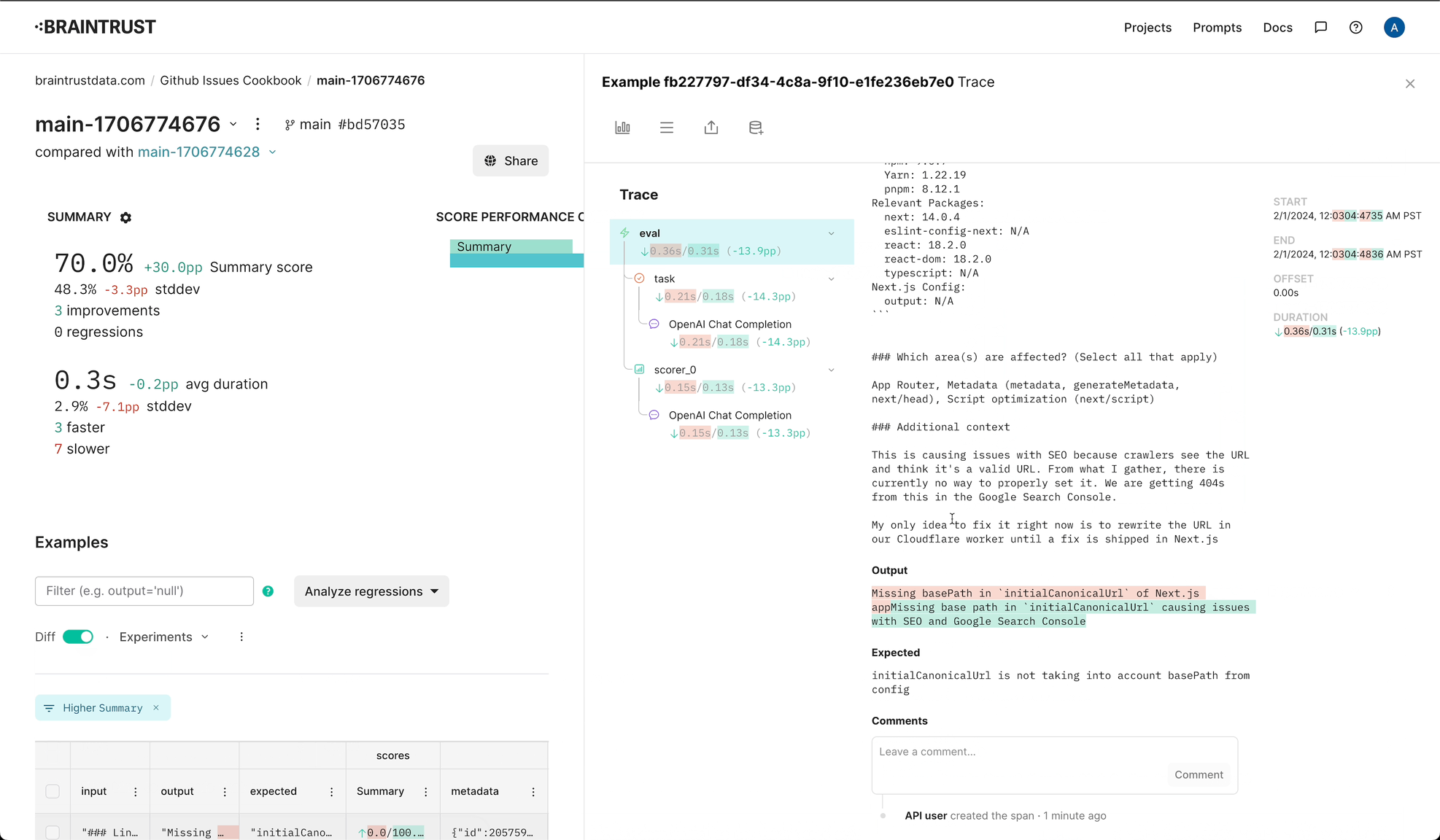
console.log("Done!");Great! We got an initial result. If you follow the link, you'll see an eval result showing an initial score of 40%.
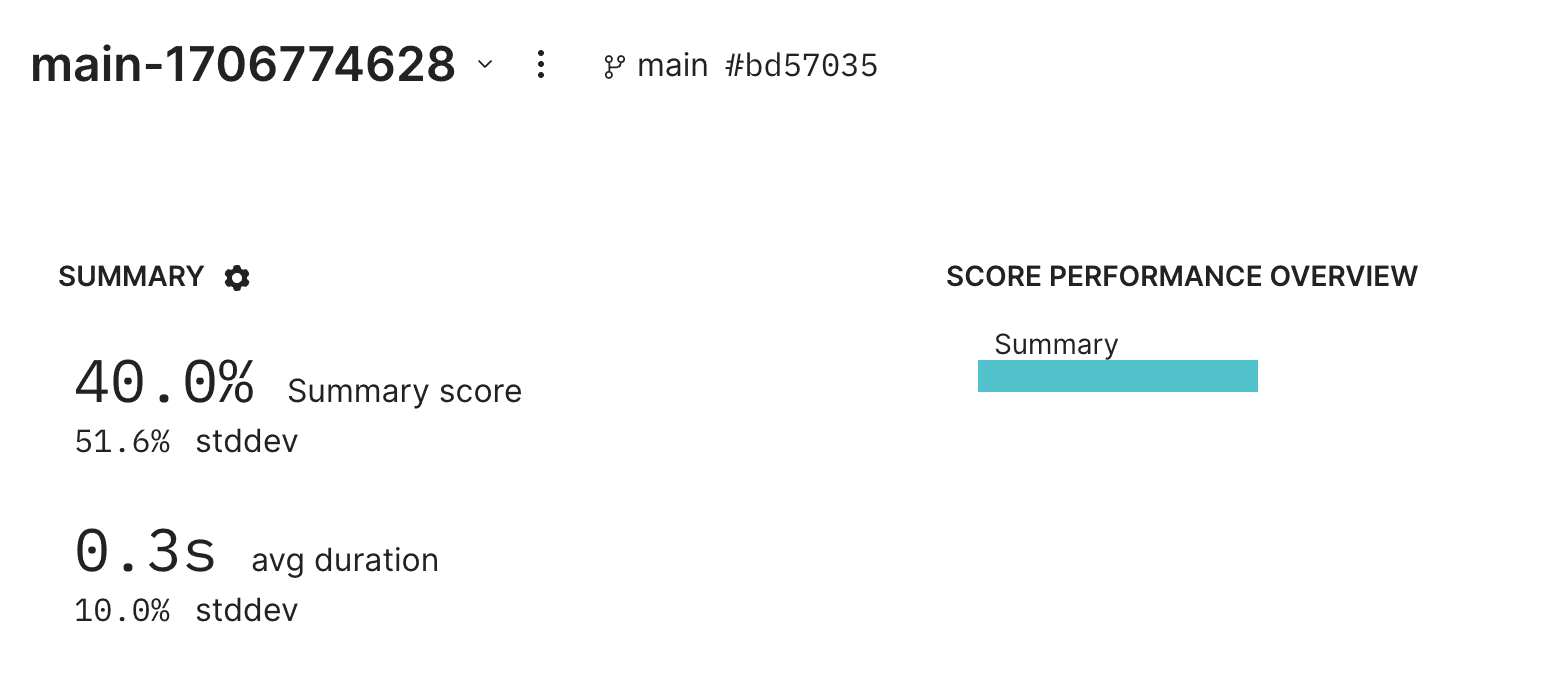
Debugging failures
Let's dig into a couple examples to see what's going on. Thanks to the instrumentation we added earlier, we can see the model's reasoning for its scores.
Issue https://github.com/vercel/next.js/issues/59995:


Issue https://github.com/vercel/next.js/issues/59986:


Improving the prompt
Hmm, it looks like the model is missing certain key details. Let's see if we can improve our prompt to encourage the model to include more details, without being too verbose.
function titleGeneratorMessages(content: string): ChatCompletionMessageParam[] {
return [
{
role: "system",
content: `Generate a new title based on the github issue. The title should include all of the key
identifying details of the issue, without being longer than one line. Return just the title.`,
},
{
role: "user",
content: "Github issue: " + content,
},
];
}
async function generateTitle(input: string) {
const messages = titleGeneratorMessages(input);
const response = await client.chat.completions.create({
model: "gpt-3.5-turbo",
messages,
seed: 123,
});
return response.choices[0].message.content || "";
}Re-evaluating
Now that we've tweaked our prompt, let's see how it performs by re-running our eval.
await Eval("Github Issues Cookbook", {
data: () =>
ISSUE_DATA.map((issue) => ({
input: issue.body,
expected: issue.title,
metadata: issue,
})),
task: generateTitle,
scores: [
async ({ input, output, expected }) =>
Summary({
input,
output,
expected,
model: "gpt-4-1106-preview",
}),
],
});
console.log("All done!");Wow, with just a simple change, we're able to boost summary performance by 30%!
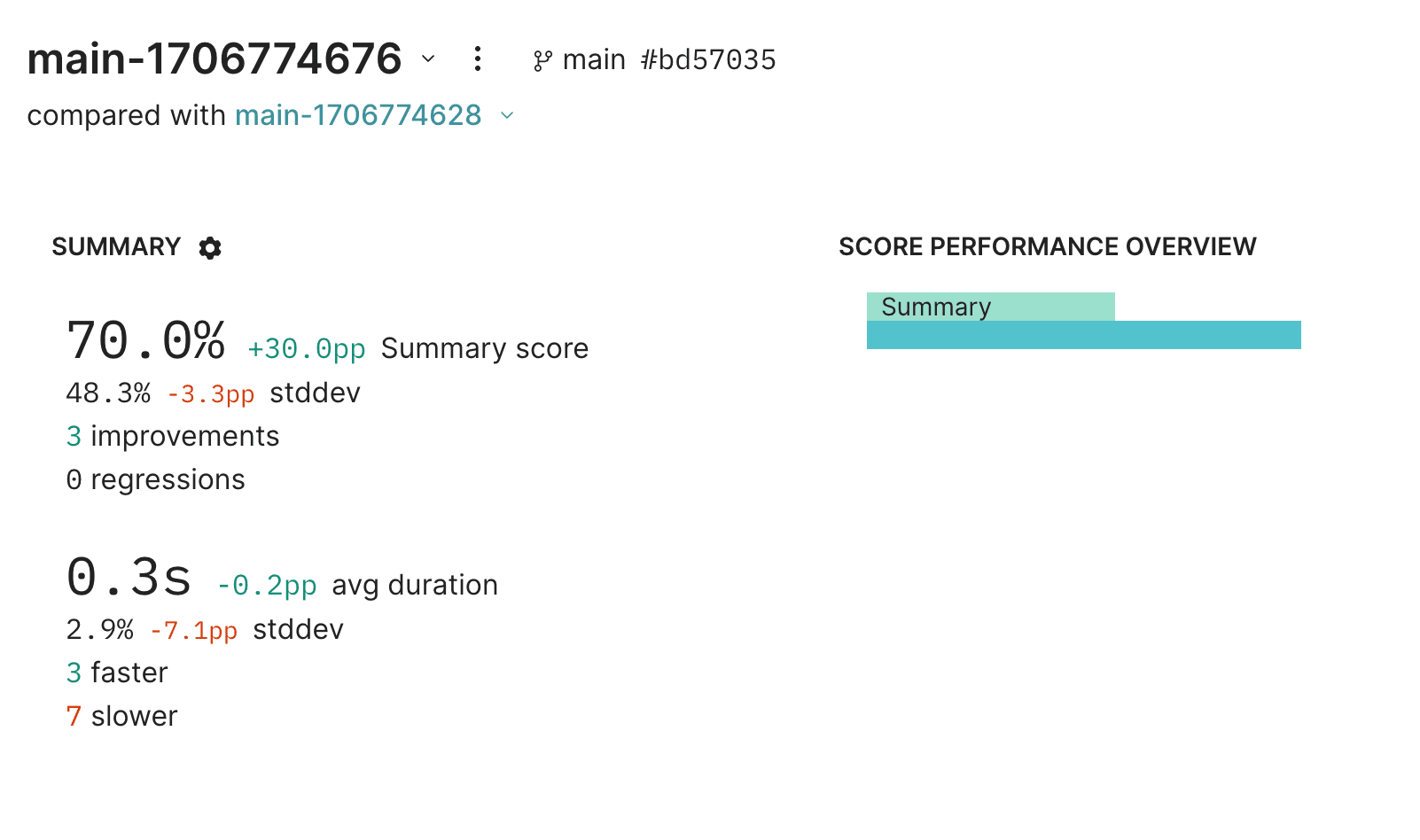
Parting thoughts
This is just the start of evaluating and improving this AI application. From here, you should dig into individual examples, verify whether they legitimately improved, and test on more data. You can even use logging to capture real-user examples and incorporate them into your evals.
Happy evaluating!