Generating release notes and hill-climbing to improve them

This tutorial walks through how to automatically generate release notes for a repository using the Github API and an LLM. Automatically generated release notes are tough to evaluate, and you often don't have pre-existing benchmark data to evaluate them on.
To work around this, we'll use hill climbing to iterate on our prompt, comparing new results to previous experiments to see if we're making progress.
Installing dependencies
To see a list of dependencies, you can view the accompanying package.json file. Feel free to copy/paste snippets of this code to run in your environment, or use tslab to run the tutorial in a Jupyter notebook.
Downloading the data
We'll start by downloading some commit data from Github using the octokit SDK. We'll use the Braintrust SDK from November 2023 through January 2024.
const START_DATE = "2023-11-26";
const END_DATE = "2024-01-27";
const REPO_OWNER = "braintrustdata";
const REPO_NAME = "braintrust-sdk";import { Octokit } from "@octokit/rest";
import { GetResponseTypeFromEndpointMethod } from "@octokit/types";
type CommitsResponse = GetResponseTypeFromEndpointMethod<
typeof octokit.rest.repos.listCommits
>;
type Commit = CommitsResponse["data"][number];
// Octokit.js
// https://github.com/octokit/core.js#readme
const octokit: Octokit = new Octokit({
auth: process.env.GITHUB_ACCESS_TOKEN || "Your Github Access Token",
});
const commits: CommitsResponse = await octokit.rest.repos.listCommits({
owner: REPO_OWNER,
repo: REPO_NAME,
since: START_DATE,
until: END_DATE,
per_page: 1000,
});
console.log("Retrieved", commits.data.length, "commits");Awesome, now let's bucket the commits into weeks.
import moment from "moment";
interface CommitInfo {
url: string;
html_url: string;
sha: string;
commit: {
author: {
name?: string;
email?: string;
date?: string;
};
message: string;
};
}
const weeks: Record<string, CommitInfo[]> = {};
for (const commit of commits.data) {
const week = moment(commit.commit.author.date, "YYYY-MM-DD")
.startOf("week")
.format("YYYY-MM-DD");
weeks[week] = (weeks[week] || []).concat([
// Simplify the commit data structure
{
sha: commit.sha,
url: commit.url,
html_url: commit.html_url,
commit: {
author: commit.commit.author,
message: commit.commit.message,
},
},
]);
}
const sortedWeeks = Object.keys(weeks).sort((a, b) =>
moment(a).diff(moment(b))
);
for (const week of sortedWeeks) {
console.log(week, weeks[week].length);
weeks[week].sort((a, b) =>
moment(a.commit.author.date).diff(moment(b.commit.author.date))
);
}Generating release notes
Awesome! It looks like we have 9 solid weeks of data to work with. Let's take a look at the first week of data.
const firstWeek = weeks[sortedWeeks[0]];
for (const commit of firstWeek) {
console.log("-----", commit.sha, "-----");
console.log(commit.html_url);
console.log(commit.commit.author.date);
console.log(commit.commit.message);
console.log("\n");
}Building the prompt
Next, we'll try to generate release notes using gpt-3.5-turbo and a relatively simple prompt.
We'll start by initializing an OpenAI client and wrapping it with some Braintrust instrumentation. wrapOpenAI
is initially a no-op, but later on when we use Braintrust, it will help us capture helpful debugging information about the model's performance.
import { wrapOpenAI } from "braintrust";
import { OpenAI } from "openai";
const client = wrapOpenAI(
new OpenAI({
apiKey: process.env.OPENAI_API_KEY || "Your OpenAI API Key",
})
);
const MODEL: string = "gpt-3.5-turbo";
const SEED = 123;import { ChatCompletionMessageParam } from "openai/resources";
import { traced } from "braintrust";
function serializeCommit(info: CommitInfo): string {
return `SHA: ${info.sha}
AUTHOR: ${info.commit.author.name} <${info.commit.author.email}>
DATE: ${info.commit.author.date}
MESSAGE: ${info.commit.message}`;
}
function generatePrompt(commits: CommitInfo[]): ChatCompletionMessageParam[] {
return [
{
role: "system",
content: `You are an expert technical writer who generates release notes for the Braintrust SDK.
You will be provided a list of commits, including their message, author, and date, and you will generate
a full list of release notes, in markdown list format, across the commits. You should include the important
details, but if a commit is not relevant to the release notes, you can skip it.`,
},
{
role: "user",
content:
"Commits: \n" + commits.map((c) => serializeCommit(c)).join("\n\n"),
},
];
}
async function generateReleaseNotes(input: CommitInfo[]) {
return traced(
async (span) => {
const response = await client.chat.completions.create({
model: MODEL,
messages: generatePrompt(input),
seed: SEED,
});
return response.choices[0].message.content;
},
{
name: "generateReleaseNotes",
}
);
}
const releaseNotes = await generateReleaseNotes(firstWeek);
console.log(releaseNotes);Evaluating the initial prompt
Interesting, at a glance, it looks like the model is doing a decent job, but it's missing some key details like the version updates. Before we go any further, let's benchmark its performance by writing an eval.
Building a scorer
Let's start by implementing a scorer that can assess how well the new release notes capture the list of commits. To make the scoring function job's easy, we'll do a few tricks:
- Use gpt-4 instead of gpt-3.5-turbo
- Only present it the commit summaries, without the SHAs or author info, to reduce noise.
import { LLMClassifierFromTemplate, Scorer, Score } from "autoevals";
const GRADER: string = "gpt-4";
const promptTemplate = `You are a technical writer who helps assess how effectively a product team generates
release notes based on git commits. You will look at the commit messages and determine if the release
notes sufficiently cover the changes.
Messages:
{{input}}
Release Notes:
{{output}}
Assess the quality of the release notes by selecting one of the following options. As you think through
the changes, list out which messages are not included in the release notes or info that is made up.
a) The release notes are excellent and cover all the changes.
b) The release notes capture some, but not all, of the changes.
c) The release notes include changes that are not in the commit messages.
d) The release notes are not useful and do not cover any changes.`;
const evaluator: Scorer<any, { input: string; output: string }> =
LLMClassifierFromTemplate<{ input: string }>({
name: "Comprehensiveness",
promptTemplate,
choiceScores: { a: 1, b: 0.5, c: 0.25, d: 0 },
useCoT: true,
model: GRADER,
});
async function comprehensiveness({
input,
output,
}: {
input: CommitInfo[];
output: string;
}): Promise<Score> {
return evaluator({
input: input.map((c) => "-----\n" + c.commit.message).join("\n\n"),
output,
});
}
await comprehensiveness({ input: firstWeek, output: releaseNotes });Let's also score the output's writing quality. We want to make sure the release notes are well-written, concise, and do not contain repetitive content.
const promptTemplate = `You are a technical writer who helps assess the writing quality of release notes.
Release Notes:
{{output}}
Assess the quality of the release notes by selecting one of the following options. As you think through
the changes, list out which messages are not included in the release notes or info that is made up.
a) The release notes are clear and concise.
b) The release notes are not formatted as markdown/html, but otherwise are well written.
c) The release notes contain superfluous wording, for example statements like "let me know if you have any questions".
d) The release notes contain repeated information.
e) The release notes are off-topic to Braintrust's software and do not contain relevant information.`;
const evaluator: Scorer<any, { output: string }> = LLMClassifierFromTemplate({
name: "WritingQuality",
promptTemplate,
choiceScores: { a: 1, b: 0.75, c: 0.5, d: 0.25, e: 0 },
useCoT: true,
model: GRADER,
});
async function writingQuality({ output }: { output: string }): Promise<Score> {
return evaluator({
output,
});
}
await writingQuality({ output: releaseNotes });import { Eval } from "braintrust";
let lastExperiment = await Eval<CommitInfo[], string, unknown>(
"Release Notes Cookbook",
{
data: Object.entries(weeks).map(([week, commits]) => ({
input: commits,
metadata: { week },
})),
task: generateReleaseNotes,
scores: [comprehensiveness, writingQuality],
}
);Wow! We're doing a great job with writing quality, but scored lower on comprehensiveness.
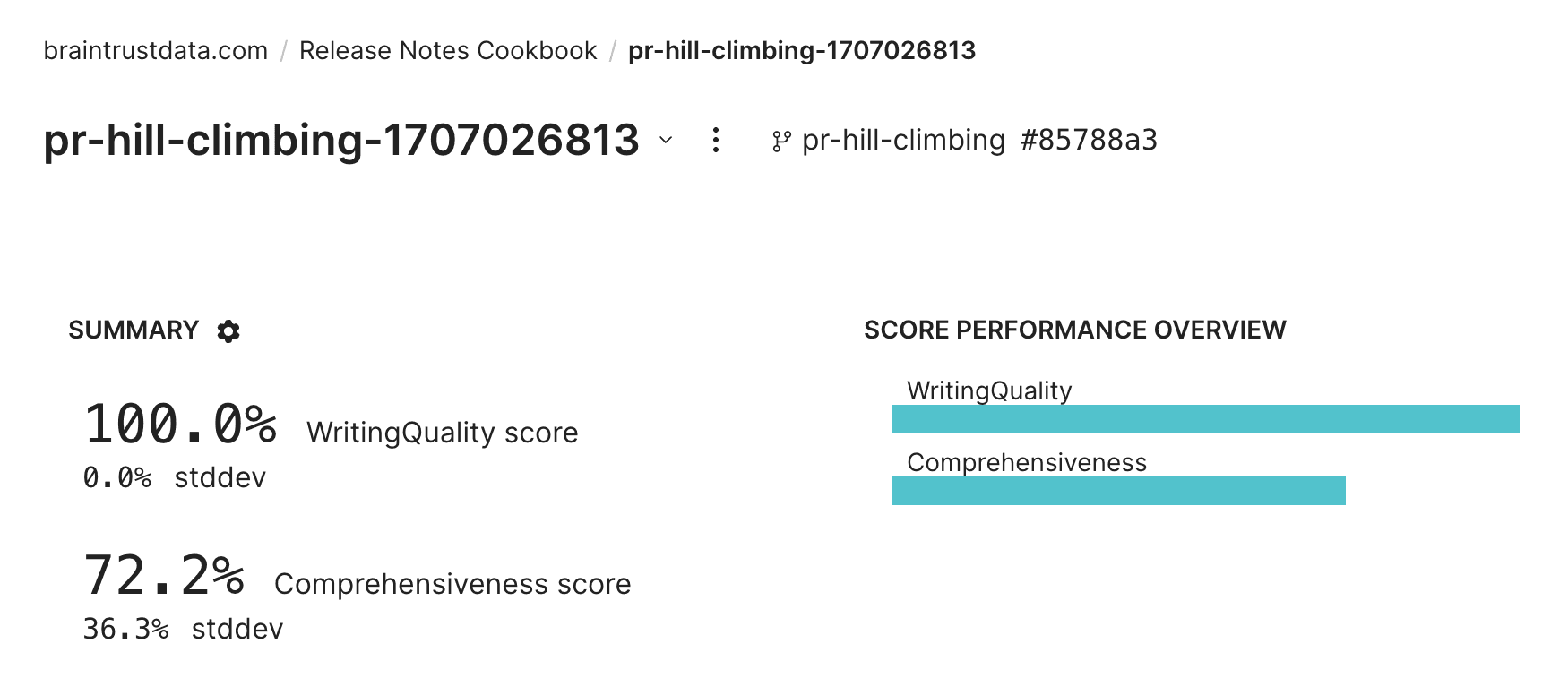
Braintrust makes it easy to see concrete examples of the failure cases. For example this grader mentions the new lazy login behavior is missing from the release notes:
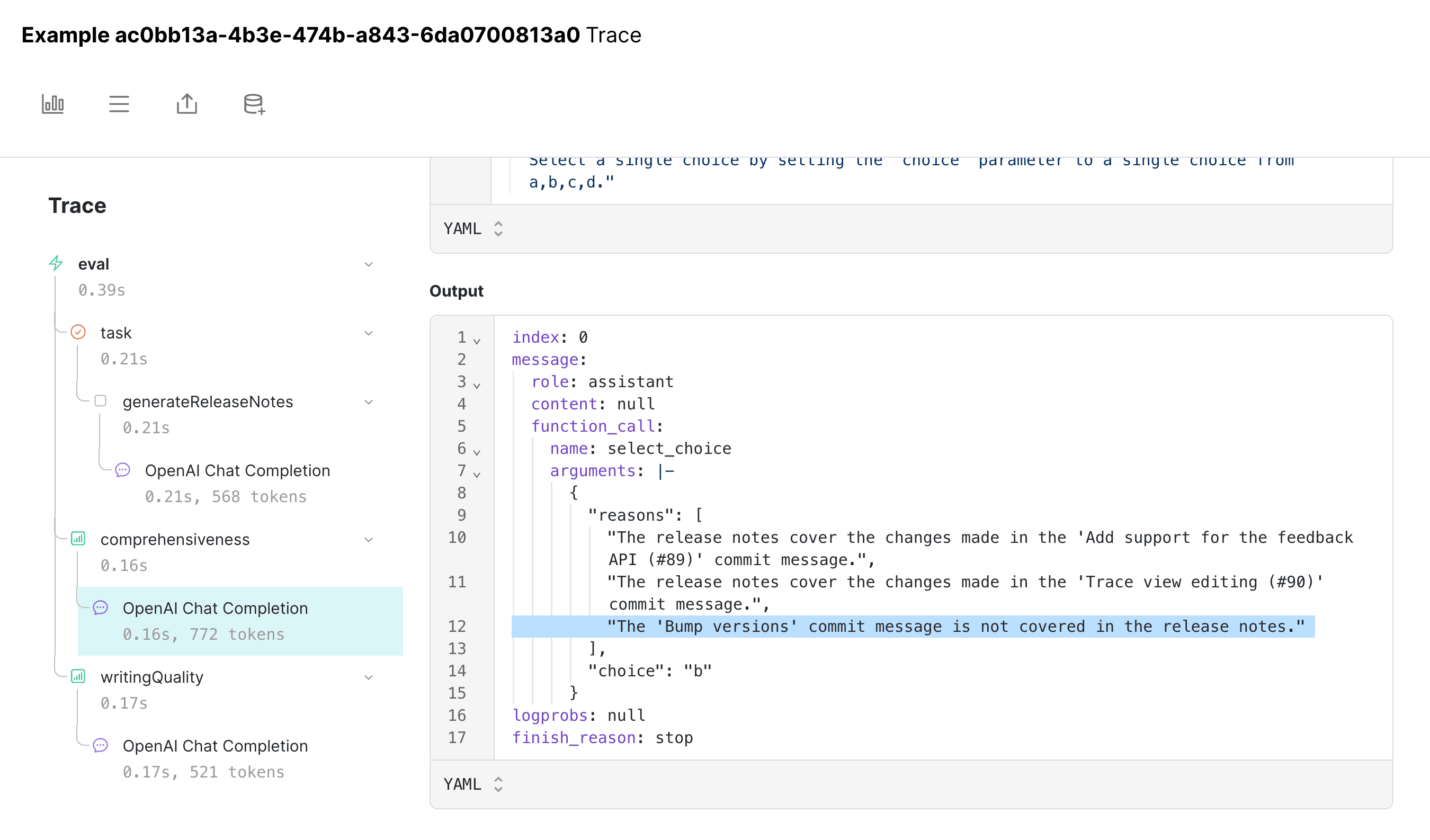
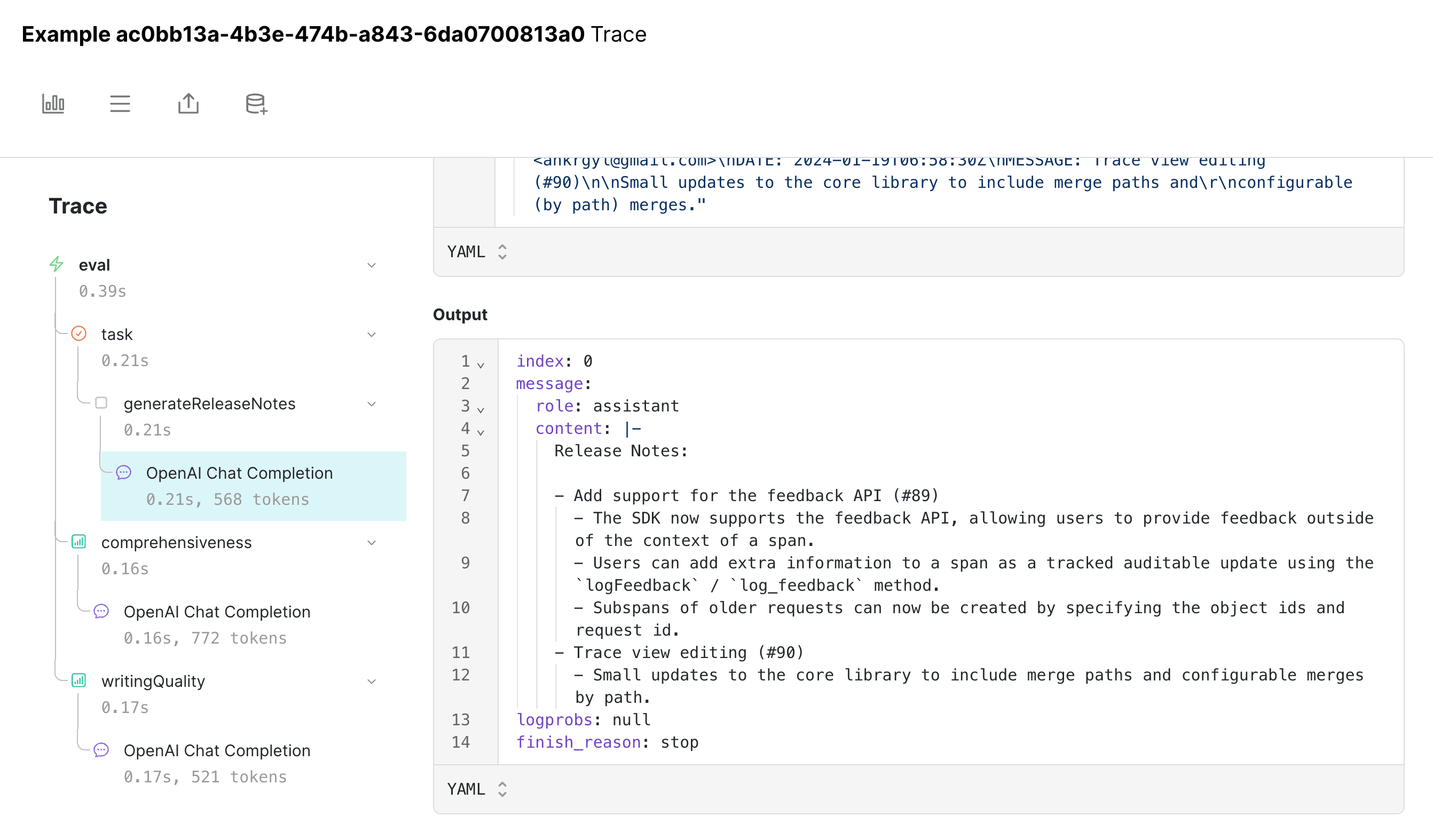
and if we click into the model's output, we can see that it's indeed missing:
Improving the prompt
Let's see if we can improve the model's performance by tweaking the prompt. Perhaps we were too eager about excluding irrelevant details in the original prompt. Let's tweak the wording to make sure it's comprehensive.
function generatePrompt(commits: CommitInfo[]): ChatCompletionMessageParam[] {
return [
{
role: "system",
content: `You are an expert technical writer who generates release notes for the Braintrust SDK.
You will be provided a list of commits, including their message, author, and date, and you will generate
a full list of release notes, in markdown list format, across the commits. You should make sure to include
some information about each commit, without the commit sha, url, or author info.`,
},
{
role: "user",
content:
"Commits: \n" + commits.map((c) => serializeCommit(c)).join("\n\n"),
},
];
}
async function generateReleaseNotes(input: CommitInfo[]) {
return traced(
async (span) => {
const response = await client.chat.completions.create({
model: MODEL,
messages: generatePrompt(input),
seed: SEED,
});
return response.choices[0].message.content;
},
{
name: "generateReleaseNotes",
}
);
}
await generateReleaseNotes(firstWeek);Hill climbing
We'll use hill climbing to automatically use data from the previous experiment to compare to this one. Hill climbing is inspired by, but not exactly the same as, the term used in numerical optimization. In the context of Braintrust, hill climbing is a way to iteratively improve a model's performance by comparing new experiments to previous ones. This is especially useful when you don't have a pre-existing benchmark to evaluate against.
Both the Comprehensiveness and WritingQuality scores evaluate the output against the input, without considering a comparison point. To take advantage of hill climbing, we'll add another scorer, Summary, which will compare the output against the data from the previous experiment. To learn more about the Summary scorer, check out its prompt.
To enable hill climbing, we just need to use BaseExperiment() as the data argument to Eval(). The name argument is optional, but since we know the exact experiment to compare to, we'll specify it. If you don't specify a name, Braintrust will automatically use the most recent ancestor on your main branch or the last experiment by timestamp as the comparison point.
import { BaseExperiment } from "braintrust";
import { Summary } from "autoevals";
async function releaseSummary({
input,
output,
expected,
}: {
input: CommitInfo[];
output: string;
expected: string;
}): Promise<Score> {
return Summary({
input: input.map((c) => "-----\n" + c.commit.message).join("\n\n"),
output,
expected,
model: GRADER,
useCoT: true,
});
}
lastExperiment = await Eval<CommitInfo[], string, unknown>(
"Release Notes Cookbook",
{
data: BaseExperiment({ name: lastExperiment.experimentName }),
task: generateReleaseNotes,
scores: [comprehensiveness, writingQuality, releaseSummary],
}
);While we were able to boost the comprehensiveness score to 86%, it looks like we dropped the writing quality score by 25%.
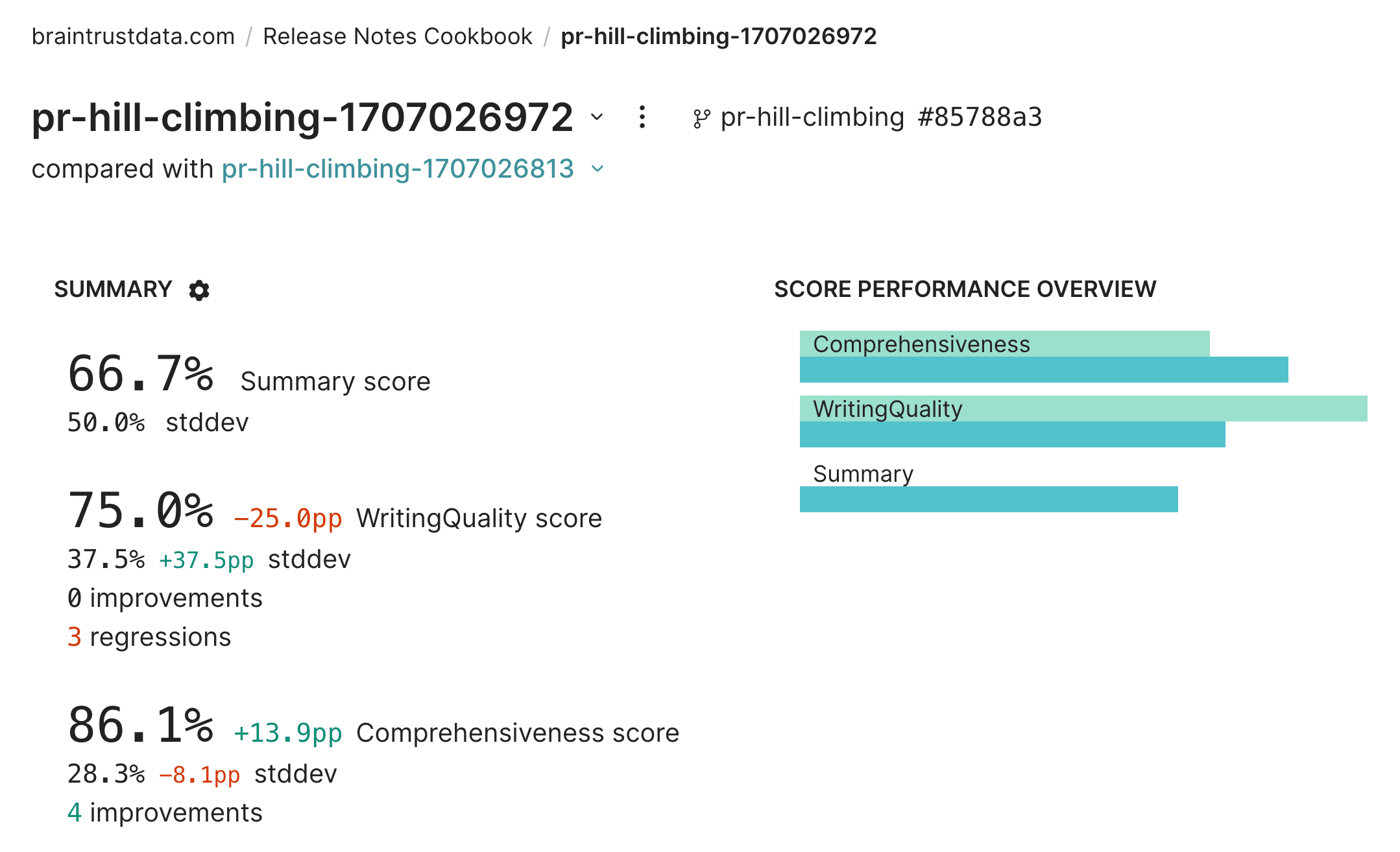
Digging into a few examples, it appears that we're mentioning version bumps multiple times.
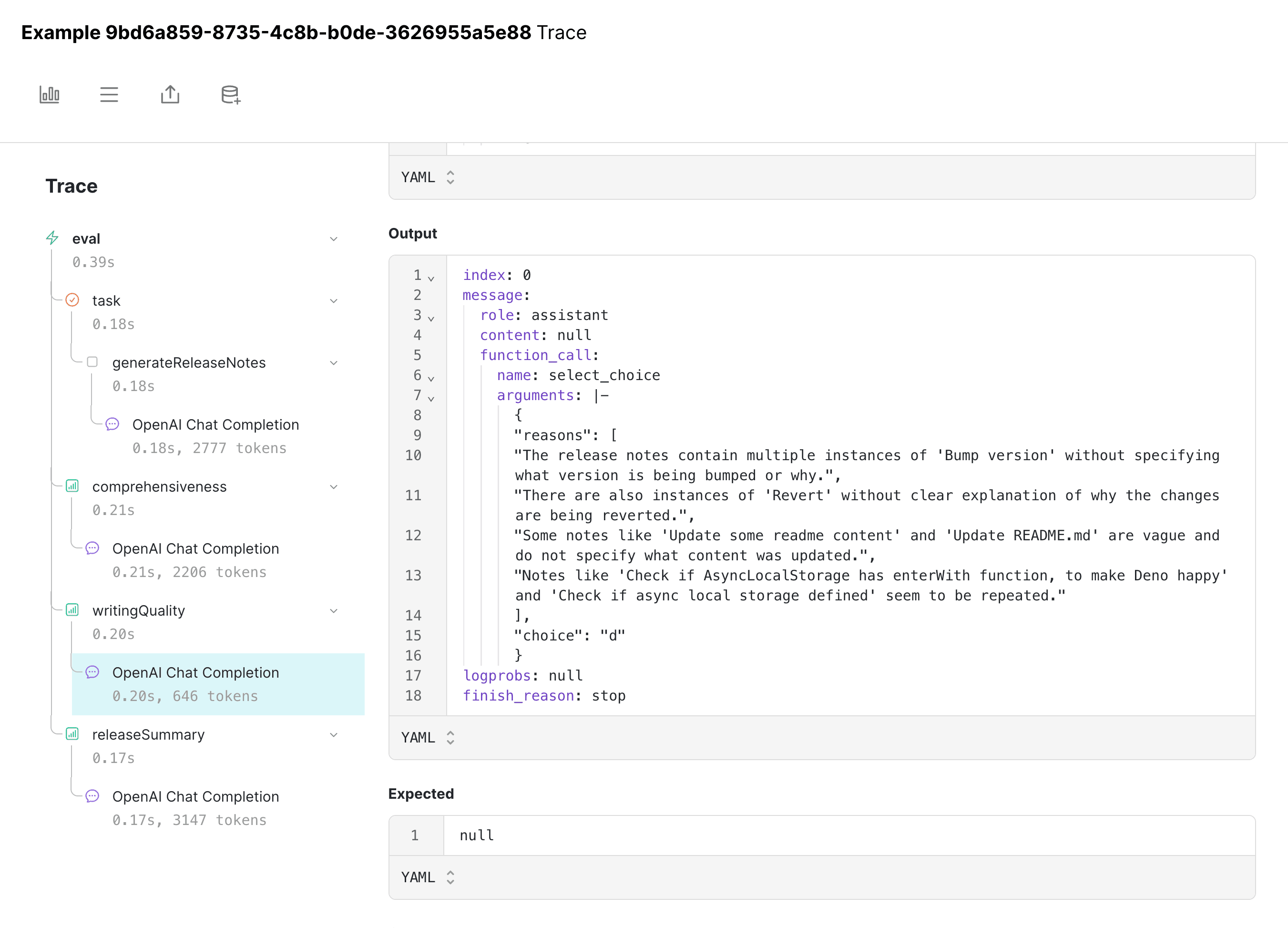
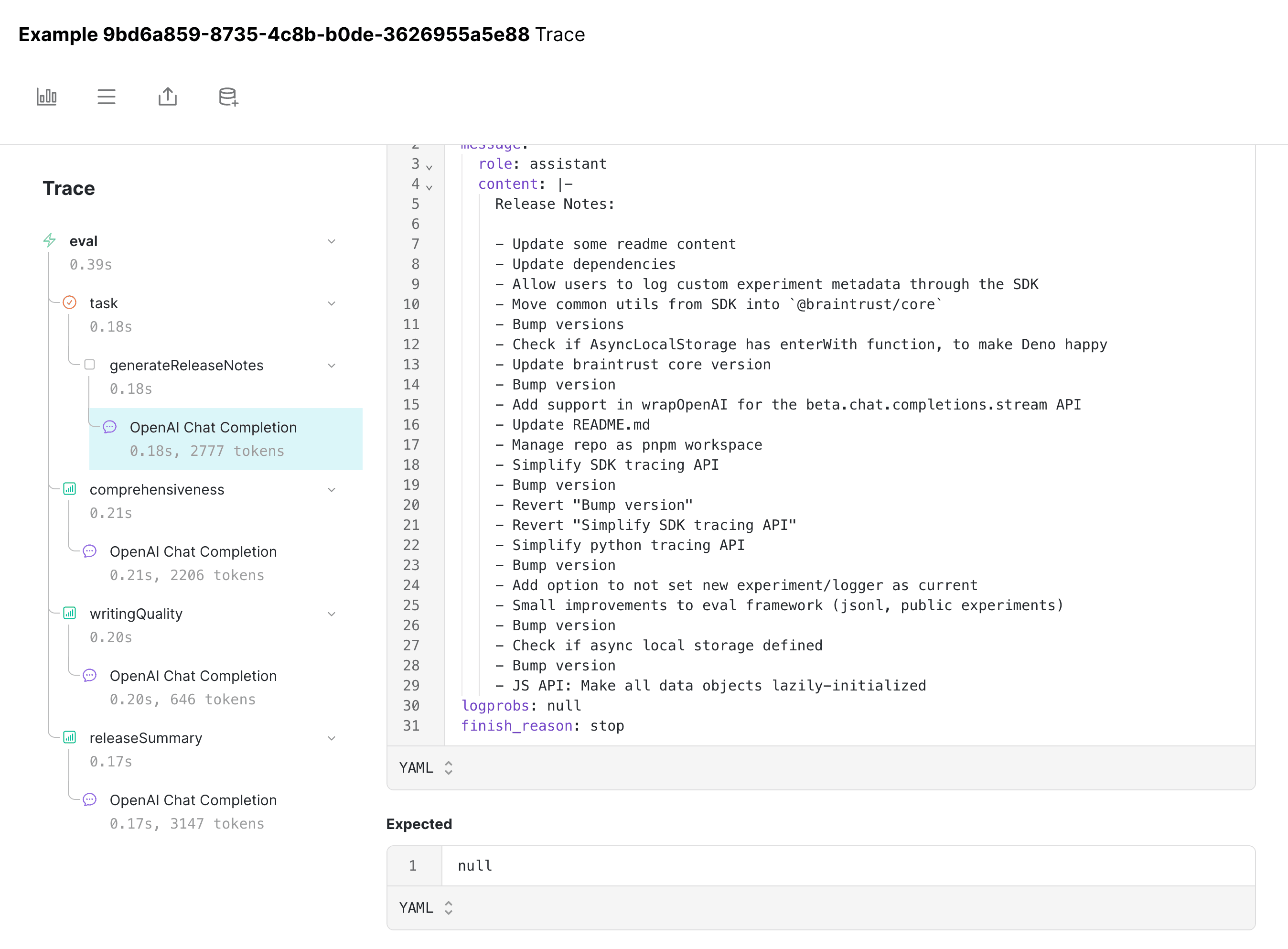
Iterating further on the prompt
Let's try to address this explicitly by tweaking the prompt. We'll continue to hill climb.
import { ChatCompletionMessageParam } from "openai/resources";
import { traced } from "braintrust";
function generatePrompt(commits: CommitInfo[]): ChatCompletionMessageParam[] {
return [
{
role: "system",
content: `You are an expert technical writer who generates release notes for the Braintrust SDK.
You will be provided a list of commits, including their message, author, and date, and you will generate
a full list of release notes, in markdown list format, across the commits. You should make sure to include
some information about each commit, without the commit sha, url, or author info. However, do not mention
version bumps multiple times. If there are multiple version bumps, only mention the latest one.`,
},
{
role: "user",
content:
"Commits: \n" + commits.map((c) => serializeCommit(c)).join("\n\n"),
},
];
}
async function generateReleaseNotes(input: CommitInfo[]) {
return traced(
async (span) => {
const response = await client.chat.completions.create({
model: MODEL,
messages: generatePrompt(input),
seed: SEED,
});
return response.choices[0].message.content;
},
{
name: "generateReleaseNotes",
}
);
}
const releaseNotes = await generateReleaseNotes(firstWeek);
console.log(releaseNotes);lastExperiment = await Eval<CommitInfo[], string, unknown>(
"Release Notes Cookbook",
{
data: BaseExperiment({ name: lastExperiment.experimentName }),
task: generateReleaseNotes,
scores: [comprehensiveness, writingQuality, releaseSummary],
}
);Sometimes hill climbing is not a linear process. It looks like while we've improved the writing quality, we've now dropped the comprehensiveness score as well as overall summary quality.
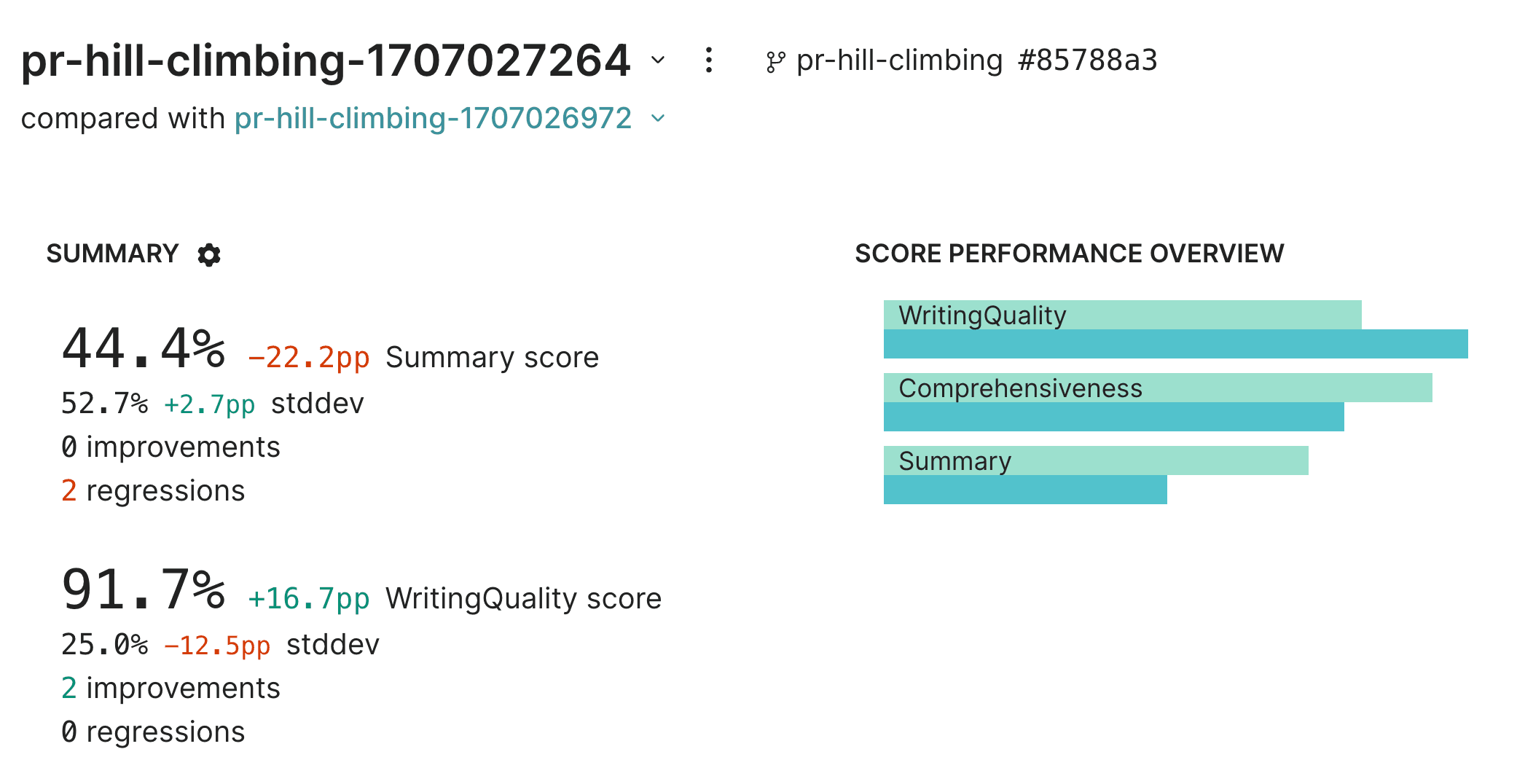
Upgrading the model
Let's try upgrading the model to gpt-4-1106-turbo and see if that helps. Perhaps we're hitting the limits of gpt-3.5-turbo.
async function generateReleaseNotes(input: CommitInfo[]) {
return traced(
async (span) => {
const response = await client.chat.completions.create({
model: "gpt-4-1106-preview",
messages: generatePrompt(input),
seed: SEED,
});
return response.choices[0].message.content;
},
{
name: "generateReleaseNotes",
}
);
}lastExperiment = await Eval<CommitInfo[], string, unknown>(
"Release Notes Cookbook",
{
data: BaseExperiment({ name: lastExperiment.experimentName }),
task: generateReleaseNotes,
scores: [comprehensiveness, writingQuality, releaseSummary],
}
);Wow, nice! It looks like we've made an improvement across the board.
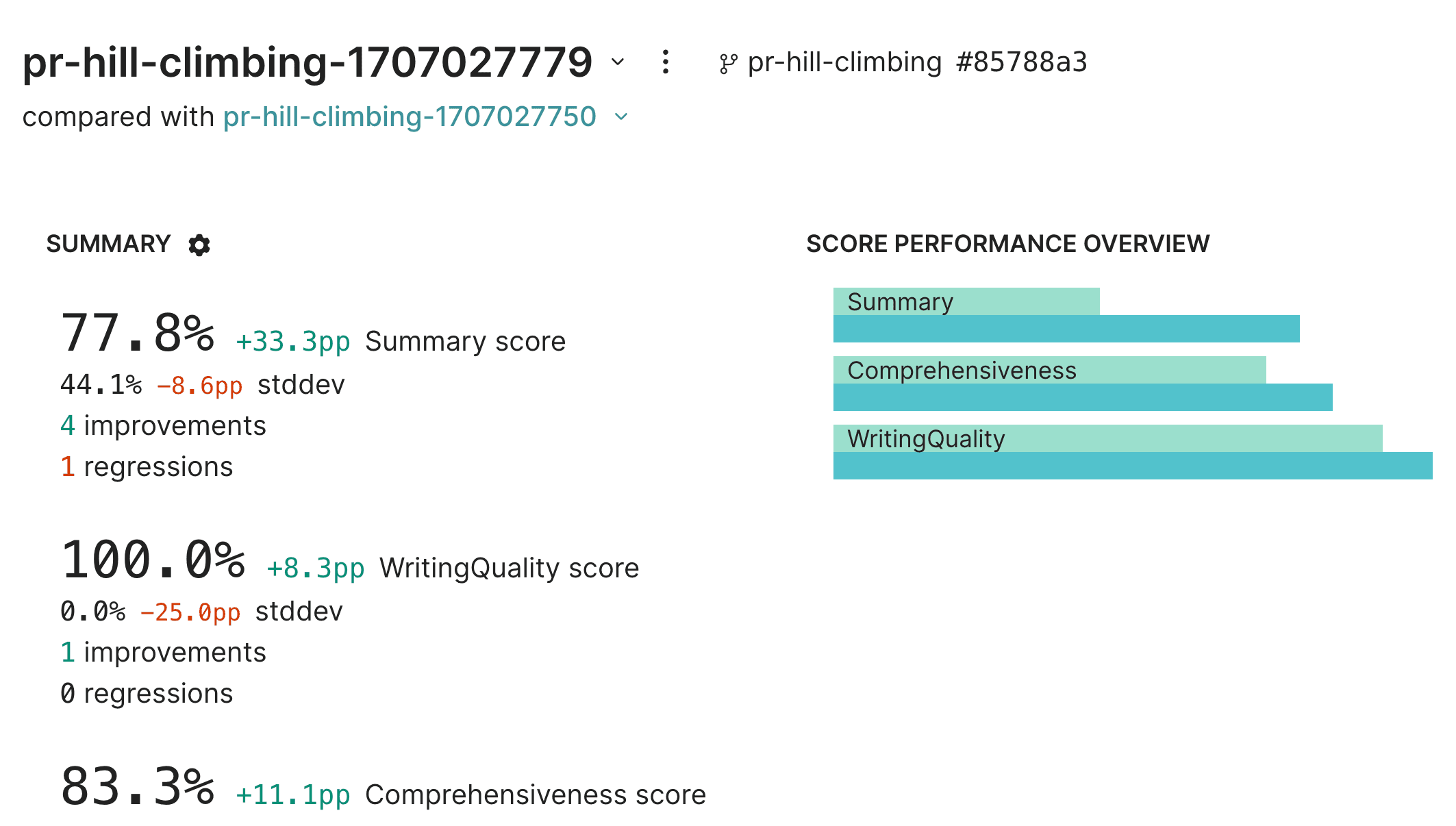
As a next step, we should dig into the example where we produced a worse summary than before, and hypothesize how to improve it.

Happy evaluating!