Text-to-SQL

This tutorial will teach you how to create an application that converts natural language questions into SQL queries, and then evaluating how well the queries work. We'll even make an improvement to the prompts, and evaluate the impact! By the time you finish this tutorial, you should be ready to run your own experiments.
Before starting, please make sure that you have a BrainTrust account. If you do not, please sign up.
Setting up the environment
The next few commands will install some libraries and include some helper code for the text2sql application. Feel free to copy/paste/tweak/reuse this code in your own tools.
!pip install braintrust duckdb datasets openai pyarrow python-LevenshteinWe're going to use a public dataset called WikiSQL that contains natural language questions and their corresponding SQL queries.
Exploring the data
In this section, we'll take a look at the dataset and ground truth text/sql pairs to better understand the problem and data.
from datasets import load_dataset
data = list(load_dataset("wikisql")["test"])Here's an example question:
idx = 1
data[idx]["question"]We'll use Arrow and DuckDB to help us explore the data and run SQL queries on it:
import duckdb
import pyarrow as pa
def get_table(table):
rows = [{h: row[i] for (i, h) in enumerate(table["header"])} for row in table["rows"]]
return pa.Table.from_pylist(rows)
table = get_table(data[idx]["table"])
duckdb.arrow(table).query("table", 'SELECT * FROM "table"')In WikiSQL, the queries are formatted as a series of projection and filter expressions. Although there is a human_readable field, it's not valid SQL!
data[idx]["sql"]Let's define a codegen_query function that turns it into executable SQL.
def esc_fn(s):
return f'''"{s.replace('"', '""')}"'''
def esc_value(s):
if isinstance(s, str):
return s.replace("'", "''")
else:
return s
def codegen_query(query):
header = query["table"]["header"]
projection = f"{esc_fn(header[query['sql']['sel']])}"
agg_op = AGG_OPS[query["sql"]["agg"]]
if agg_op is not None:
projection = f"{agg_op}({projection})"
conds = query["sql"]["conds"]
filters = " and ".join(
[
f"""{esc_fn(header[field])}{COND_OPS[cond]}'{esc_value(value)}'"""
for (field, cond, value) in zip(
conds["column_index"], conds["operator_index"], conds["condition"]
)
]
)
if filters:
filters = f" WHERE {filters}"
return f'SELECT {projection} FROM "table"{filters}'
gt_sql = codegen_query(data[idx])
print(gt_sql)Now, we can run this SQL directly.
duckdb.arrow(table).query("table", gt_sql)import duckdb
import pyarrow as pa
from datasets import load_dataset
from Levenshtein import distance
NUM_TEST_EXAMPLES = 10
# Define some helper functions
AGG_OPS = [None, "MAX", "MIN", "COUNT", "SUM", "AVG"]
COND_OPS = [" ILIKE ", ">", "<"] # , "OP"]
def green(s):
return "\x1b[32m" + s + "\x1b[0m"
def run_query(sql, table_record):
table = get_table(table_record) # noqa
rel_from_arrow = duckdb.arrow(table)
result = rel_from_arrow.query("table", sql).fetchone()
if result and len(result) > 0:
return result[0]
return None
def score(r1, r2):
if r1 is None and r2 is None:
return 1
if r1 is None or r2 is None:
return 0
r1, r2 = str(r1), str(r2)
total_len = max(len(r1), len(r2))
return 1 - distance(r1, r2) / total_lenRunning your first experiment
In this section, we'll create our first experiment and analyze the results in BrainTrust.
import os
from braintrust import wrap_openai
from openai import OpenAI
client = wrap_openai(OpenAI(api_key=os.environ.get("OPENAI_API_KEY", "Your OPENAI_API_KEY here")))
def text2sql(input):
table = input["table"]
meta = "\n".join(f'"{h}"' for h in table["header"])
messages = [
{
"role": "system",
"content": f"""
Print a SQL query (over a table named "table" quoted with double quotes) that answers the question below.
You have the following columns:
{meta}
The user will provide a question. Reply with a valid ANSI SQL query that answers the question, and nothing else.""",
},
{
"role": "user",
"content": f"Question: {input['question']}",
},
]
resp = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=messages,
)
sql_text = resp.choices[0].message.content
return sql_text.rstrip(";")
output_sql = text2sql(data[idx])
print(output_sql)
duckdb.arrow(table).query("table", output_sql)Exciting! Now that we've tested it out on an example, we can run an evaluation on a bigger dataset to understand how well the prompt works.
Running an eval
To run an eval, we simply need to stitch together the pieces we've already created into the Eval() function, which takes:
- The data you want to evaluate
- A
taskfunction that, given some input, returns an output - One or more scoring functions that evaluate the output.
Let's start by logging into Braintrust. You can technically skip this step if you've set BRAINTRUST_API_KEY in your environment.
import braintrust
braintrust.login(
api_key=os.environ.get("BRAINTRUST_API_KEY", "Your BRAINTRUST_API_KEY here")
)Scoring functions
Next, we need to figure out how we'll score the outputs. One way is to string compare the SQL queries. This is not a perfect signal, because two different query strings might return the correct result, but it is a useful signal about how different the generated query is from the ground truth.
from autoevals import Levenshtein
Levenshtein().eval(output=output_sql, expected=gt_sql)A more robust way to test the queries is to run them on a database and compare the results. We'll use DuckDB for this. We'll define a scoring function that runs the generated SQL and compares the results to the ground truth.
from autoevals import Score
@braintrust.traced
def result_score(output, expected, input):
expected_answer = run_query(expected, input["table"])
# These log statements allow us to see the expected and output values in the Braintrust UI
braintrust.current_span().log(expected=expected_answer)
try:
output_answer = run_query(output, input["table"])
except Exception as e:
return Score(name="SQL Result", score=0, metadata={"message": f"Error: {e}"})
braintrust.current_span().log(output=output_answer)
return Score(
name="SQL Result",
score=Levenshtein()(output=output_answer, expected=expected_answer).score,
)
result_score(output_sql, gt_sql, data[idx])from braintrust import Eval
await Eval(
"Text2SQL Cookbook",
data=[
{"input": d, "expected": codegen_query(d), "metadata": {"idx": i}}
for (i, d) in enumerate(data[:NUM_TEST_EXAMPLES])
],
task=text2sql,
scores=[Levenshtein, result_score],
)Once the eval completes, you can click on the link to see the results in the BrainTrust UI.
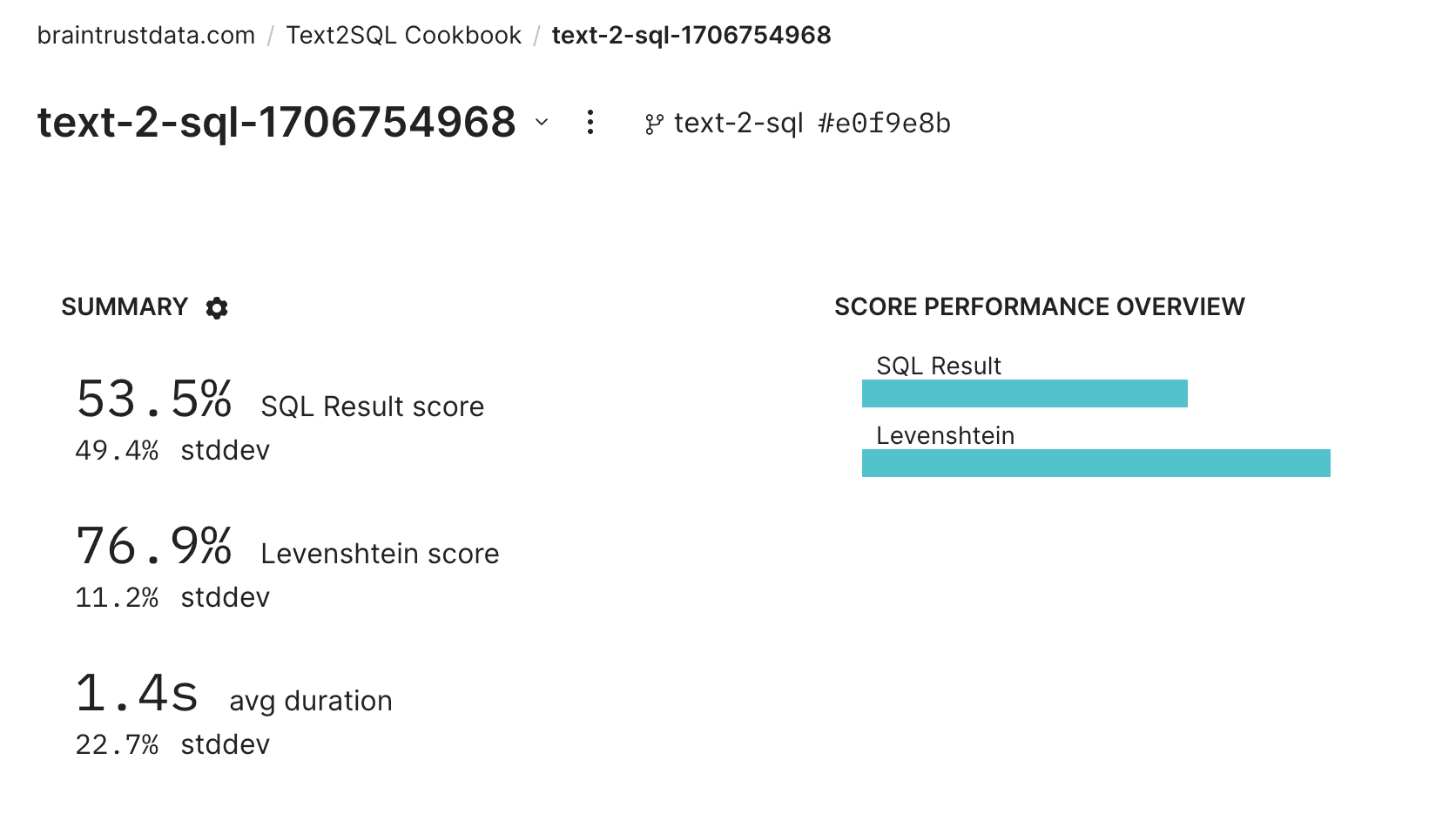
Take a look at the failures. Feel free to explore individual examples, filter down to low answer scores, etc. You should notice that idx=8 is one of the failures. Let's debug it and see if we can improve the prompt.
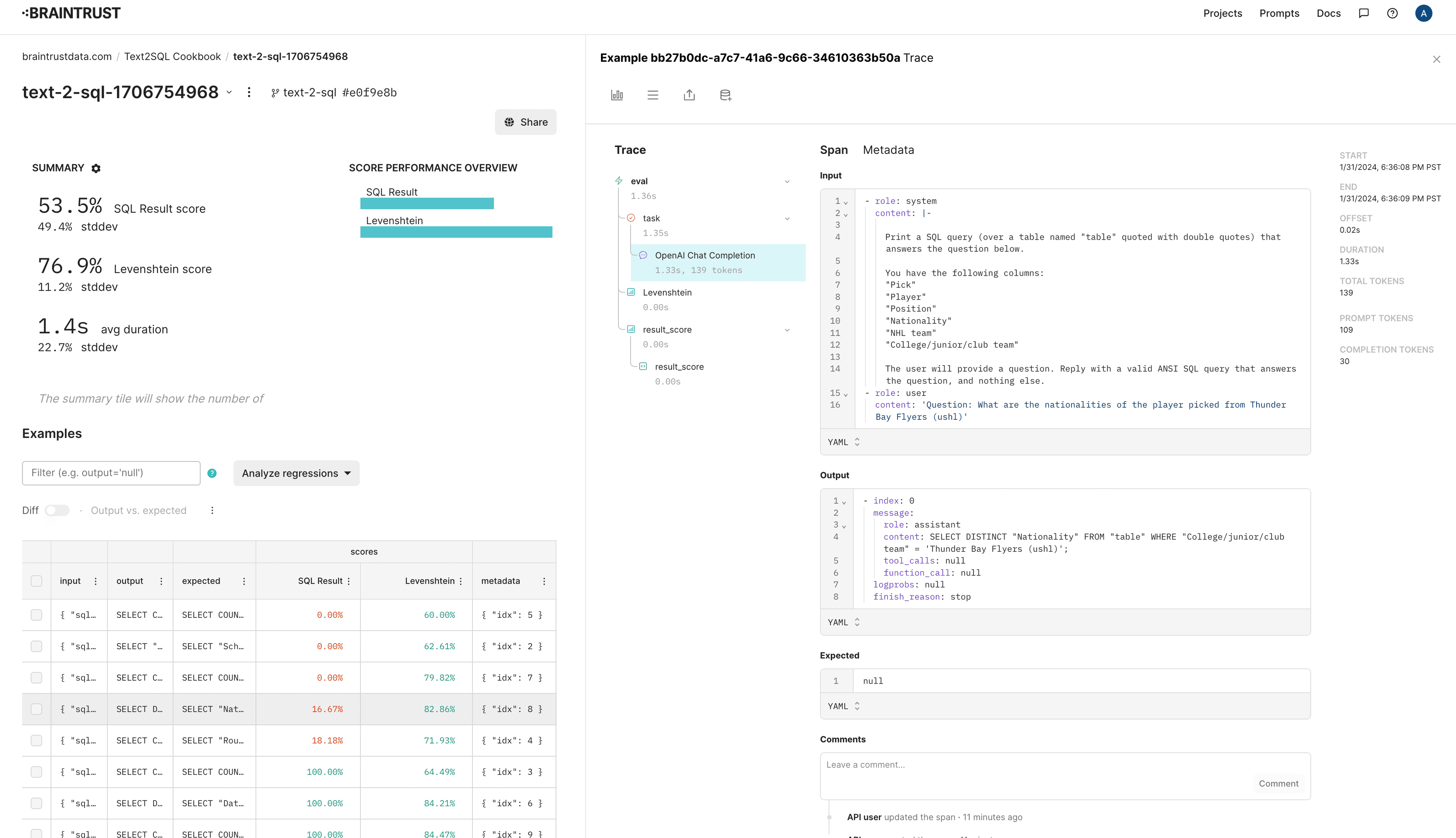
Debugging a failure
We'll first set idx=8 and reproduce the failure.
idx = 8Here is the ground truth:
print(data[idx]["question"])
table = get_table(data[idx]["table"])
print(duckdb.arrow(table).query("table", 'SELECT * FROM "table" LIMIT 5'))
gt_sql = codegen_query(data[idx])
print(gt_sql)
print(duckdb.arrow(table).query("table", gt_sql))And then what the model spits out:
output_sql = text2sql(data[idx])
print(output_sql)
duckdb.arrow(table).query("table", output_sql)Hmm, if only the model knew that 'ushl' is actually capitalized in the data. Let's fix this by providing some sample data for each column:
def text2sql(input):
table = input["table"]
rows = [
{h: row[i] for (i, h) in enumerate(table["header"])} for row in table["rows"]
]
meta = "\n".join(f'"{h}": {[row[h] for row in rows[:10]]}' for h in table["header"])
messages = [
{
"role": "system",
"content": f"""
Print a SQL query (over a table named "table" quoted with double quotes) that answers the question below.
You have the following columns (each with some sample data). Make sure to use the correct
column names for each data value:
{meta}
The user will provide a question. Reply with a valid ANSI SQL query that answers the question, and nothing else.""",
},
{
"role": "user",
"content": f"Question: {input['question']}",
},
]
resp = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=messages,
)
sql_text = resp.choices[0].message.content
return sql_text.rstrip(";")
output_sql = text2sql(data[idx])
print(output_sql)
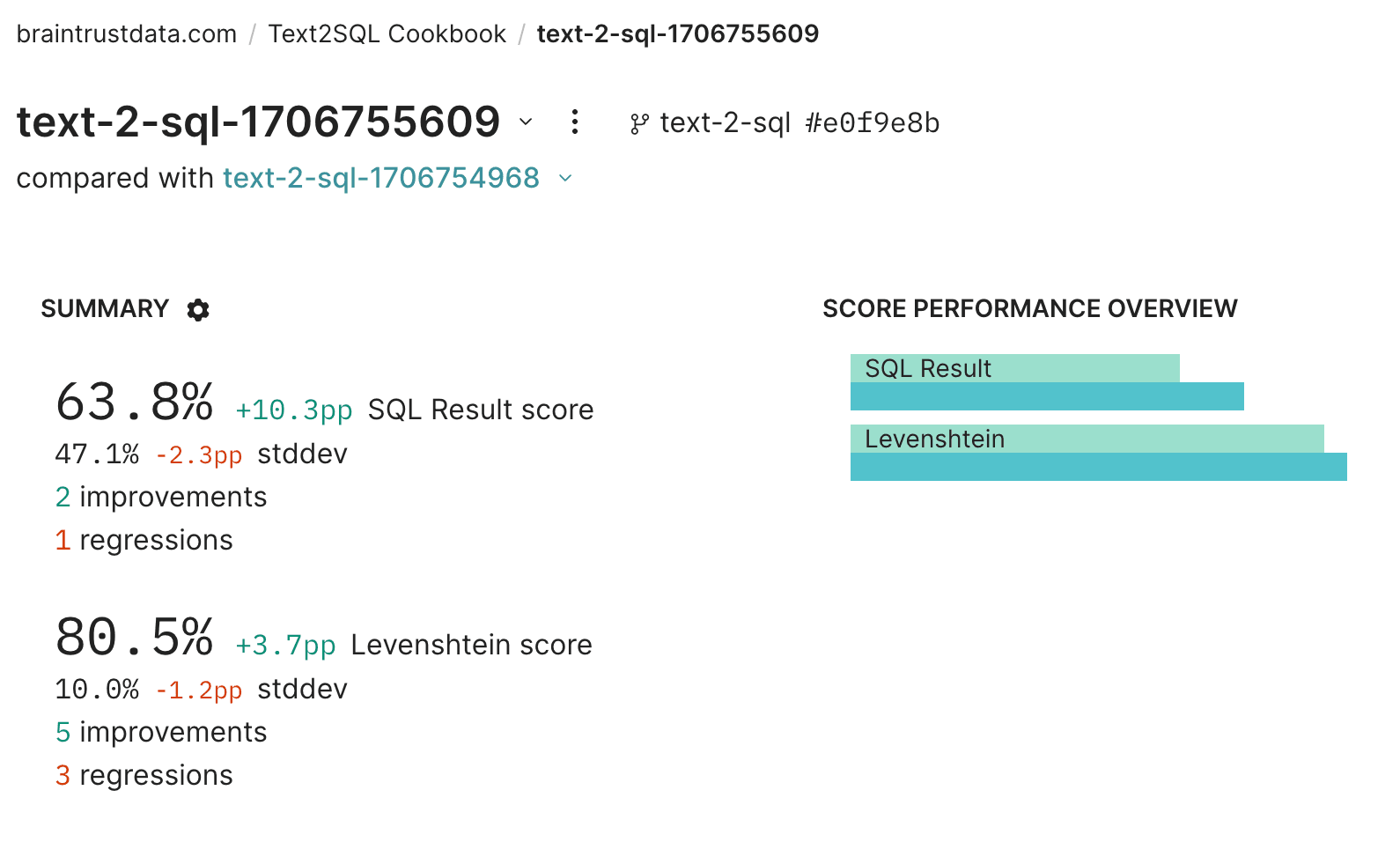
duckdb.arrow(table).query("table", output_sql)Ok great! Now let's re-run the loop with this new version of the code.
await Eval(
"Text2SQL Cookbook",
data=[
{"input": d, "expected": codegen_query(d), "metadata": {"idx": i}}
for (i, d) in enumerate(data[:NUM_TEST_EXAMPLES])
],
task=text2sql,
scores=[Levenshtein, result_score],
)
Wrapping up
Congrats 🎉. You've run your first couple of experiments. Now, return back to the tutorial docs to proceed to the next step where we'll analyze the experiments.